Visualization
sumo offers a wide range of outputs, but one may find it hard to parse and visualize them. Below, you may find some tools that allow to visualize a simulation run's results for being included in a scientific paper. Additional tools read plain .csv-files and were added to the suite as they offer a similar interface.
All these tools are just wrappers around the wonderful matplotlib library. If you are familiar with Python, you must have a look.
The tools share a set of common options to fine-tune the appearance of the generated figures. These options' names where chosen similar to the matplotlib calls.
The tools are implemented in Python and need matplotlib to be installed. The tools can be found in <SUMO_HOME>/tools/visualization.
Current Tools#
Below, you will find the descriptions of tools that should work with the current outputs sumo/sumo-gui generate. To run them, you'll need:
- to install Python
- to install matplotlib
- to set <SUMO_HOME>
All scripts are executed from the command line and you have to give the command line options as listed in the descriptions below. Please note that #common options may be applied to all the scripts listed in the following sub-sections albeit few options may not work for certain scripts.
plotXMLAttributes.py#
Create multiple 2D-plots of 2 arbitrary attributes from on or more xml files aggregated by an third attribute (i.e. detector-id).
Example uses:
python tools/visualization/plotXMLAttributes.py -x x -y y fcd.xml
python tools/visualization/plotXMLAttributes.py -x x -y y fcd.xml fcd2.xml
The above example draws the paths of all vehicles through the network based on fcd-output. (It is a special case that can also be accomplished with plot_trajectories.py)
When option --show is set, a interactive plot is opened that allows identifying data points vehicles by clicking on the plot (dataID is printed on the console).
Option --filter-ids ID1,ID2,... allows restricting the plot to the given data element ids. You can use a wildcard to filter out ids that follow some pattern; for instance --filter-ids bus_* will filter out all ids that begin with the four characters "bus_".
Further examples are shown below. Some of them are generated with the scenario acosta, one of the published sumo scenarios (https://github.com/DLR-TS/sumo-scenarios/tree/main/bologna/acosta).
Plot Styles#
The script supports the following distinct styles of plots:
- lineplot: default
- scatterplot: with option --scatterplot
- box plot: by setting one of --xattr @BOX or --yattr @BOX
- bar plot: by setting either --barplot or --hbarplot
Special Attributes#
The following attribute values have a special meaning. Instead of using an attribute from the input file they derive a value based on the other attribute. (i.e. the special attribute is set for --xattr then the other value is given by the --yattr).
@INDEX: the index of the other value within the input file is used.@FILE: the (shortened) input file name is used (useful when plotting one value per file)@RANK: the index of the other value within the sorted (descending) list of values is used@COUNT: the number of occurrences of the other value is used. Together with option --barplot or -hbarplot this gives a histogram. Binning size can be set via options --xbin and --ybin.@DENSITY: the number of occurrences of the other value is used, normalized by the total number of values.@BOX: one or more box plots of the other value are drawn. The --idattr is used for grouping and there will be one box plot per id@NONE: can be used with option --idattr to explicitly avoid grouping
Interactive Plot#
When clicking on a line or plot point, the data point ids near the click position are printed in the console.
Filtering#
Option --filter-ids ID1,ID2,... allows restricting the plot to the given data ids.
It is permitted to use the wildcars *, ?, [ and ] when specifying filters. This workings according to file name globbing rules.
Multi-line plots#
- By default, every distinct ID (as defined by --idattr) will generated a new line for all the data points associated with that ID.
- If multiple files are given, the abbreviated filename will become part of the data point ID and thereby create distinct lines or scatterpoints for data from each file
- If a comma-separated list of values is passed to option --idattr, then values for each of the attributes will be combined with
|to form the data point ID - If a comma-separated list of values given to --xattr or --yattr (or both), and the data does not supply an ID (or option --idattr @NONE is set) then each combination of individual xattr and yattr will create a new line
CSV-output#
If a combined plot is needed that cannot be created with any of the above methods (i.e. because the data comes from different kinds of data files such as summary-output and edgeData) then an alternative is to use option --csv-output and plotting the resulting data with another tool (i.e. gnuplot).
In csv-output each group of data points belonging to the same ID will form it's own block separated by two blank lines from the next block. To replicate a plot where each ID/block has its distinct color, the following approach can be used in gnuplot:
stats 'data.csv'
plot for [idx=0:STATS_blocks] 'data.csv' i idx with lines
XML format assumptions#
The default parsing engine of plotXMLAttributes assumes that each xml element occupies exactly one line in the input files. This fits with the output formatting of all SUMO applications. If an arbitrary XML file shall be plotted (i.e. without linebreaks), the option --robust-parser can be set. This will reduce processing speed.
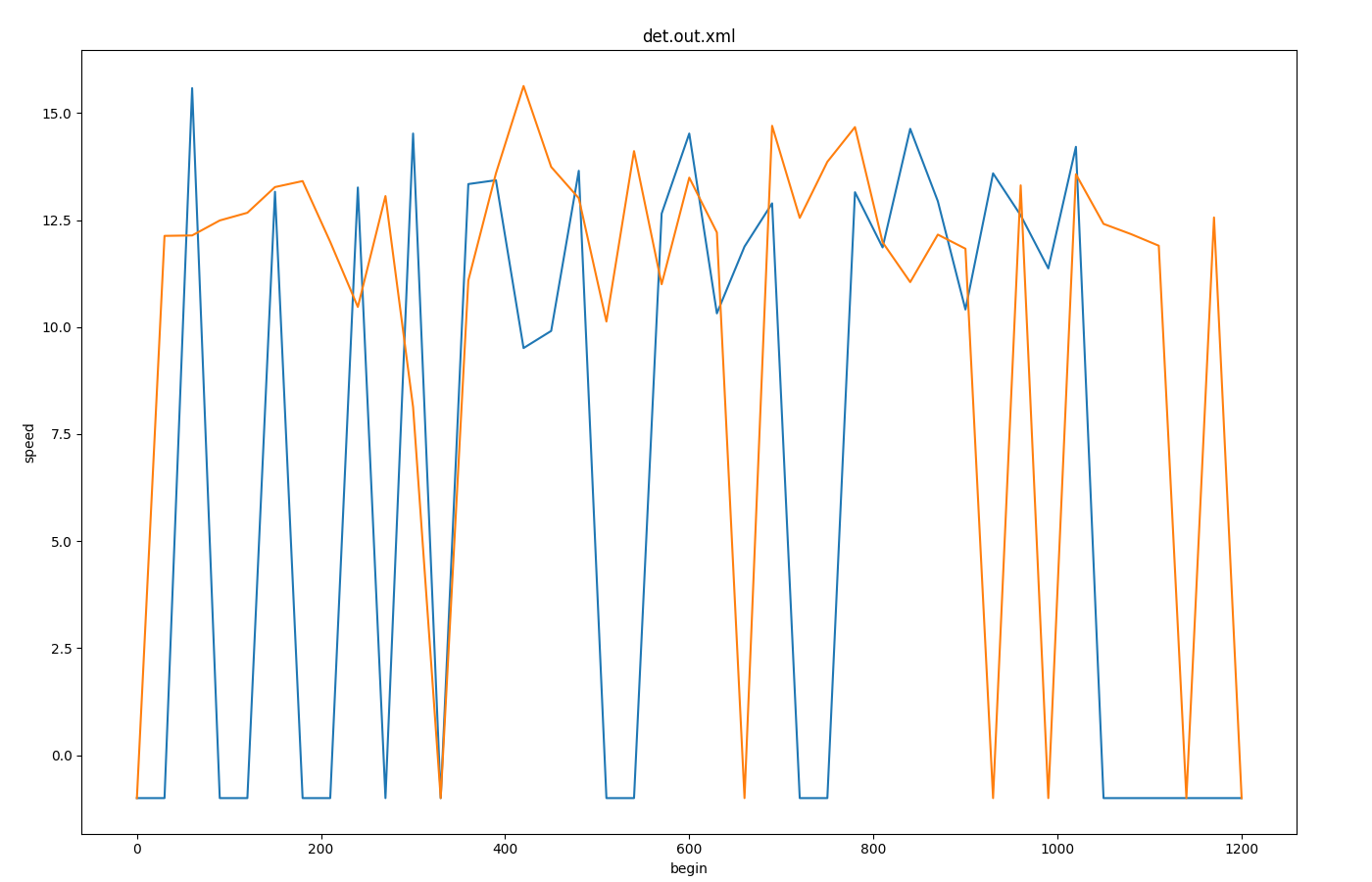
Inductionloop Speed over Time#
Input is inductionloop-output with 30s aggregation from 2 detectors (<e1Detector id="e1Detector_-109_0_0" lane="-109_0" pos="54.06" period="30.00" file="data.xml"/>
Call: python tools/visualization/plotXMLAttributes.py data.xml -x begin -y speed -s
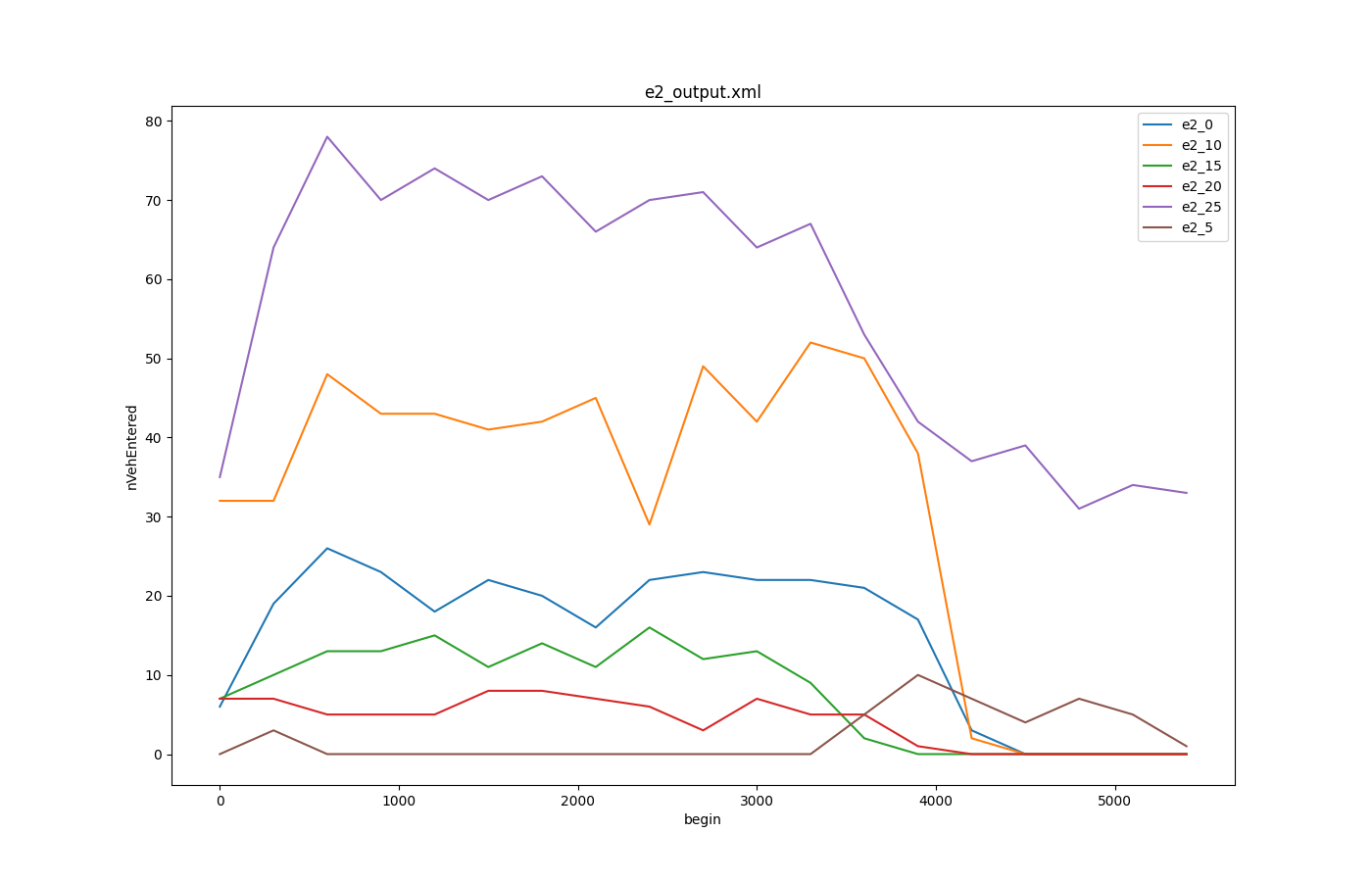
Lane Area Detectors over nVehEntered#
Input is laneareadetectors-output with 30s aggregation from 6 detectors
Call: python tools/visualization/plotXMLAttributes.py -x begin -y maxOccupancy -o plot-maxOccupancy.png --legend e2_output.xml --filter-ids e2_0,e2_5,e2_10,e2_15,e2_20,e2_25
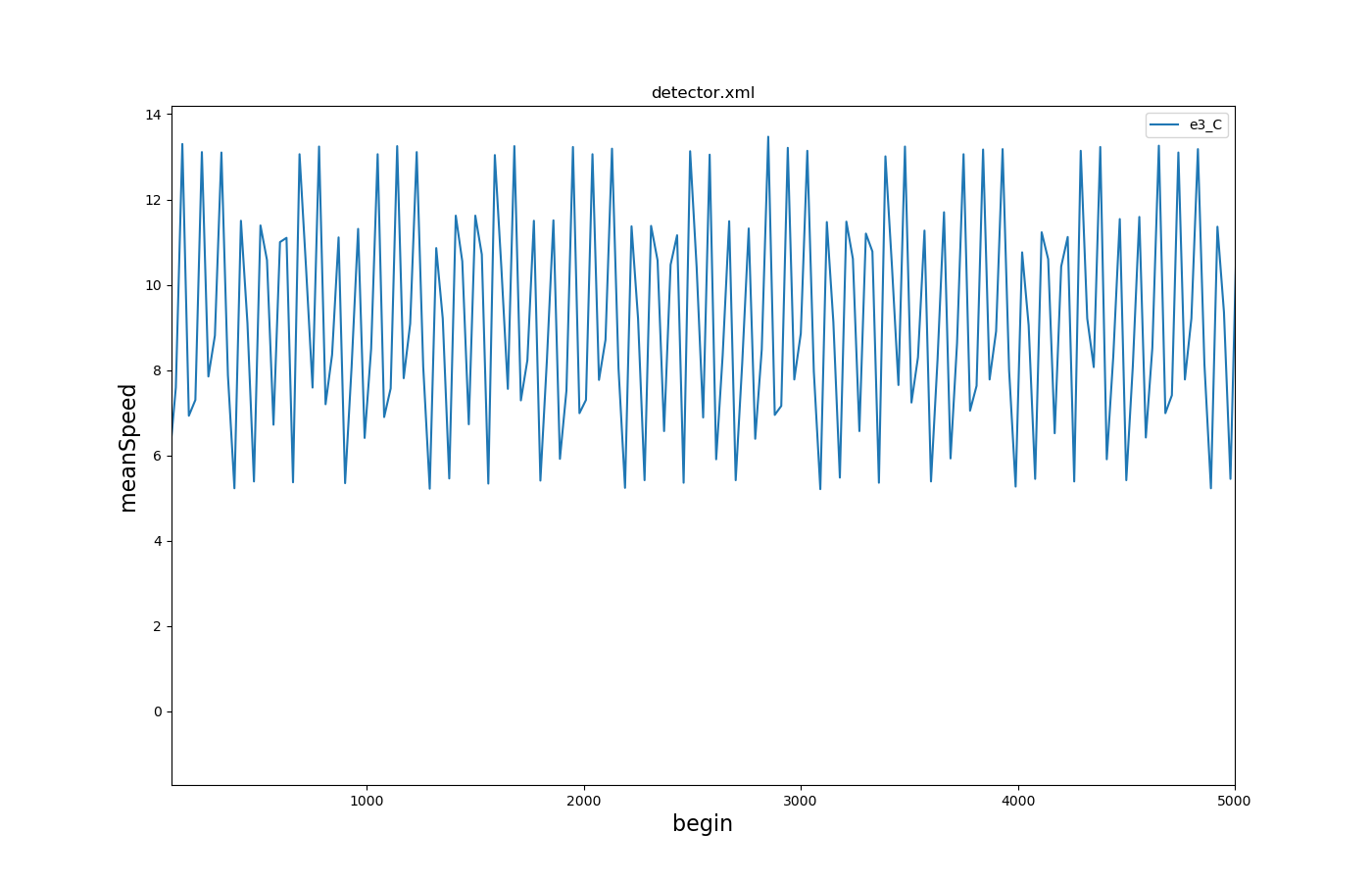
Multi-Entry-Exit Detectors Mean Speed over Time#
Input is multi-entry-exit-detector-output with 30s aggregation and a cutoff at begin and end
Call: python tools/visualization/plotXMLAttributes.py -x begin -y meanSpeed detector.xml --legend --xlim 100,5000
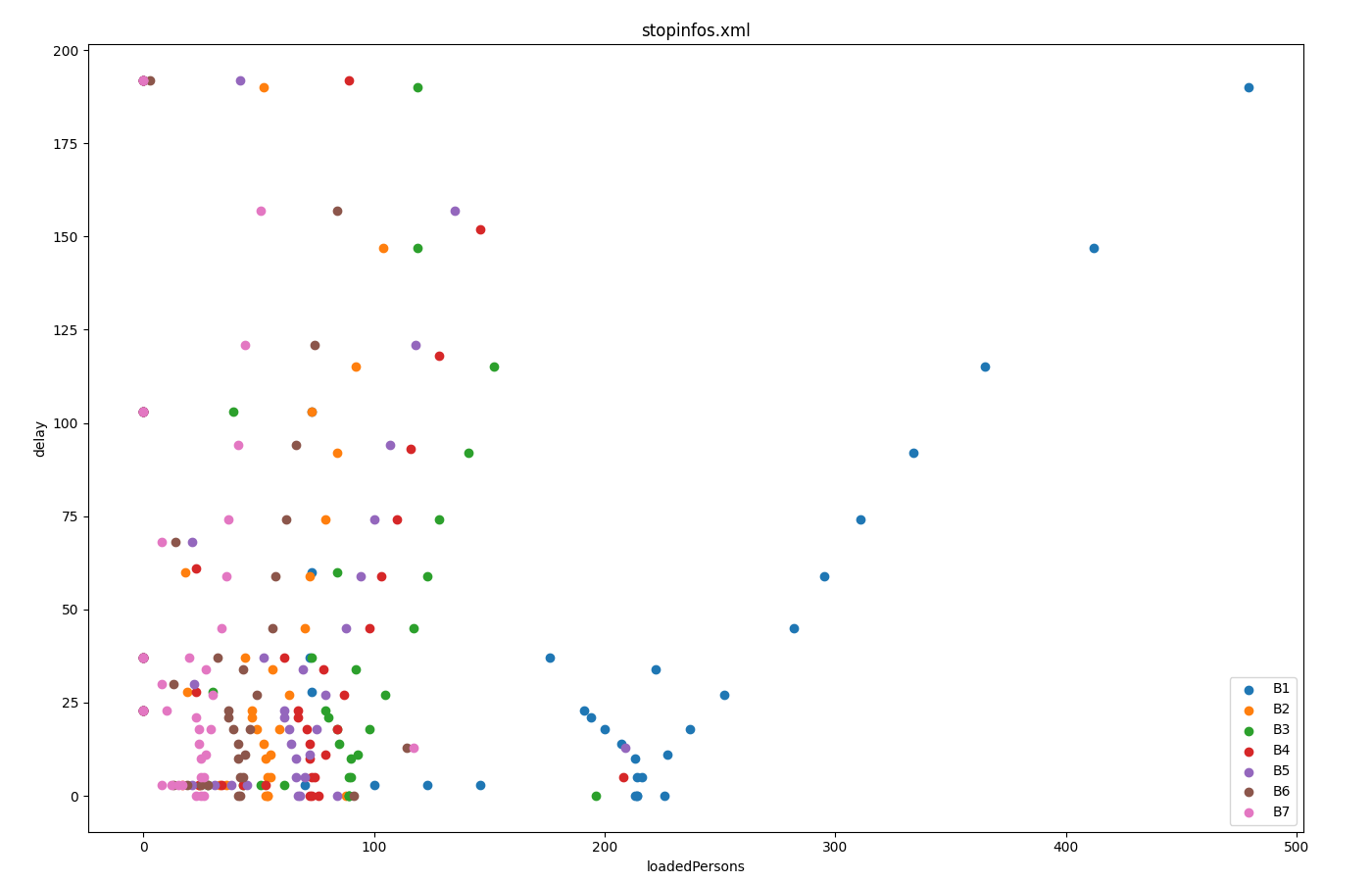
boarding passengers vs delay for each station#
Input is stop-output
Call: python tools/visualization/plotXMLAttributes.py stopinfos.xml -i busStop -x loadedPersons -y delay --scatterplot --legend
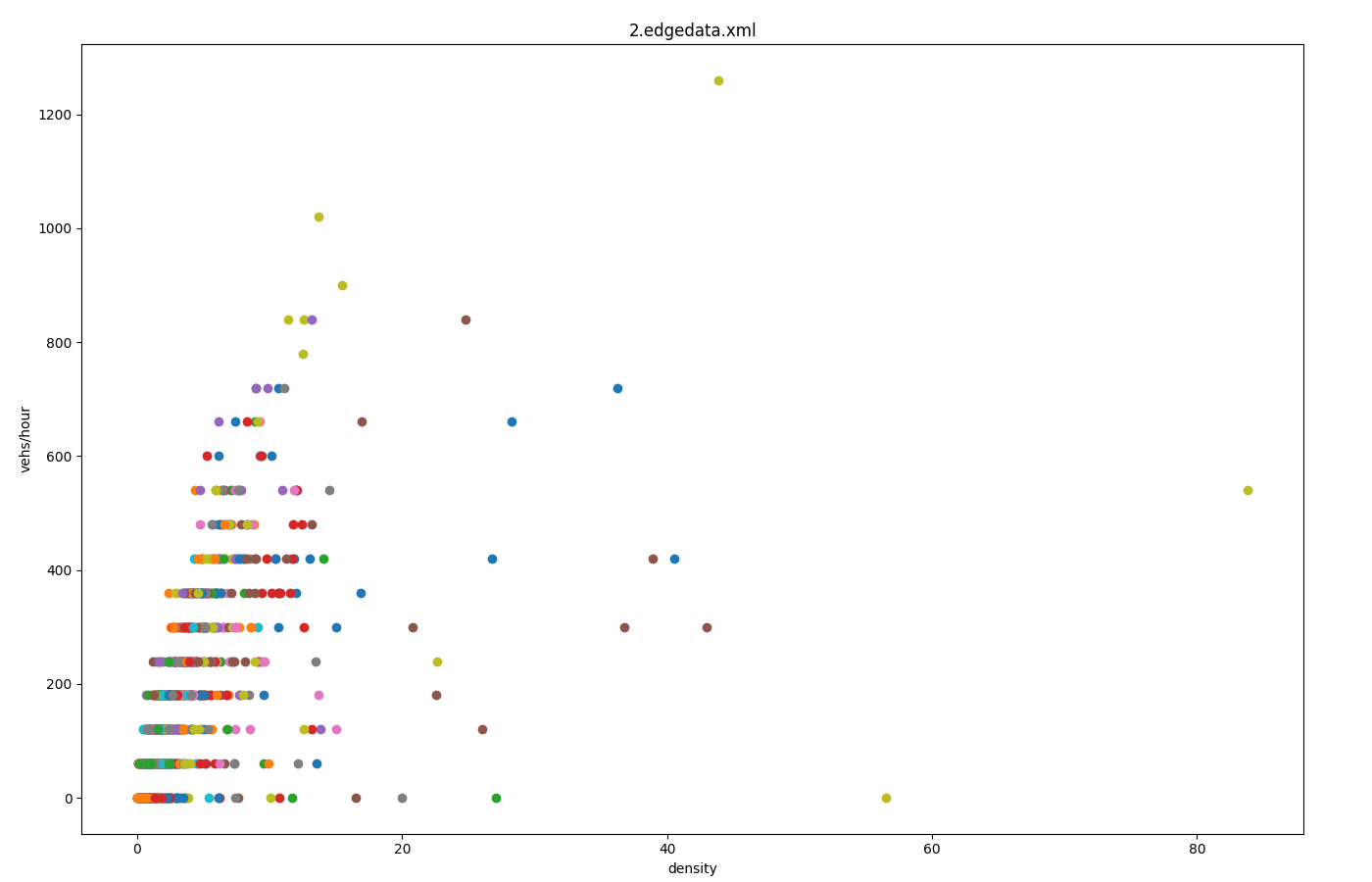
Fundamental Diagram from edgeData#
Input is edgeData-output with 1-minute aggregation (<edgeData id="example" file="data.xml" period="60"/>)
Call: python tools/visualization/plotXMLAttributes.py data.xml -i id -x density -y left --scatterplot --yfactor 60 --ylabel vehs/hour
Each color gives encodes a different edge-id. Option --factor 60 is used to convert from vehicles per 60s (edgeData-period 60) to vehicles per hour.
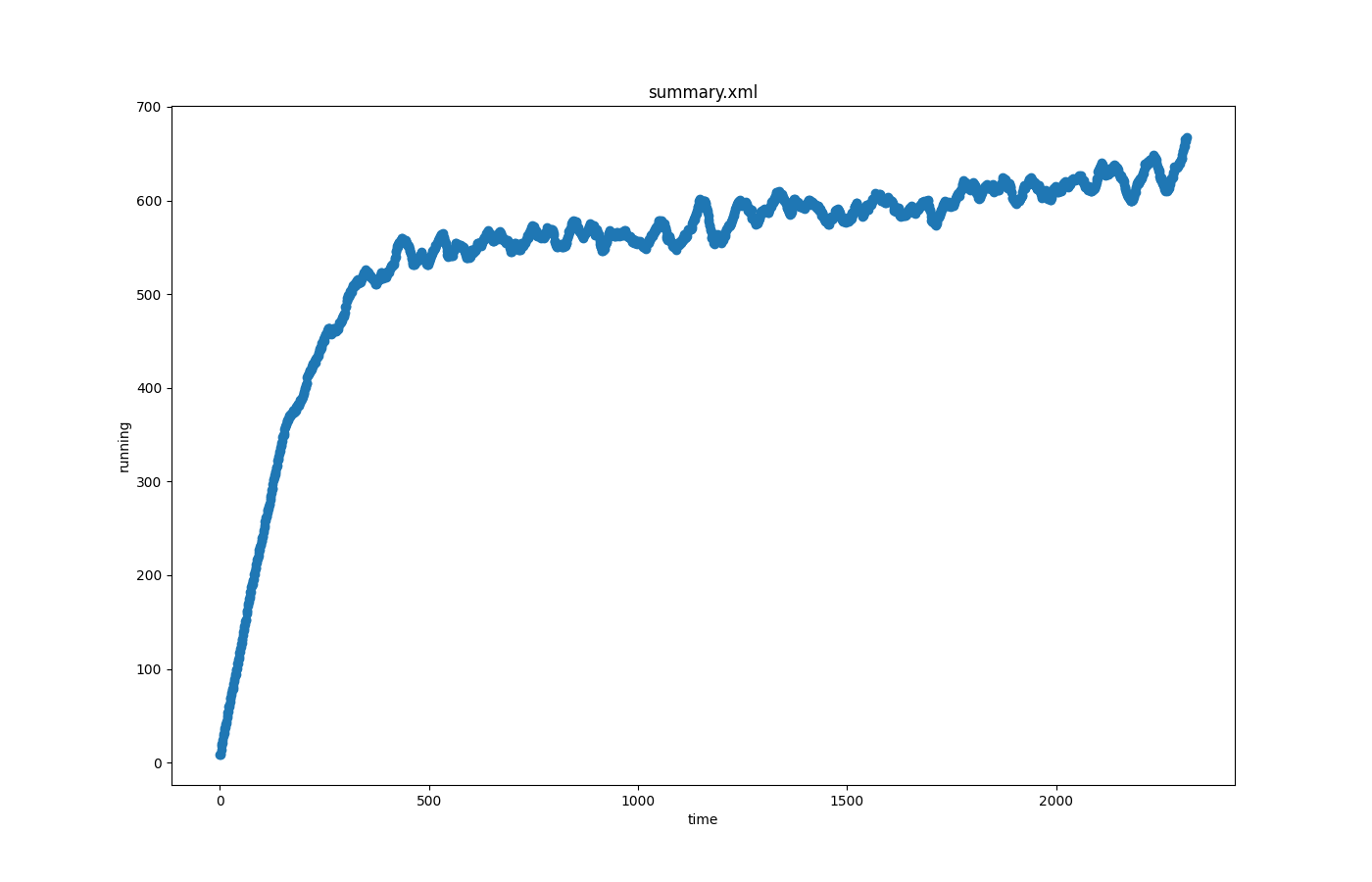
Multiple timelines from summary-output#
Input is summary. This plot demonstrates using a list of attributes to generate multiple data points from the same xml input element. In the absence of an id-attribute, the respective attribute name is used to "identify" and group the data points.
Call: python tools/visualization/plotXMLAttributes.py summary.xml -x time -y running,halting -o plot-running.png --legend
Caution
In version 1.15.0 and lower, the id-attribute must be provided so you need
to provide a dummy value (i.e. with -i collisions) and only a single value is
permitted for the x and y attribute.
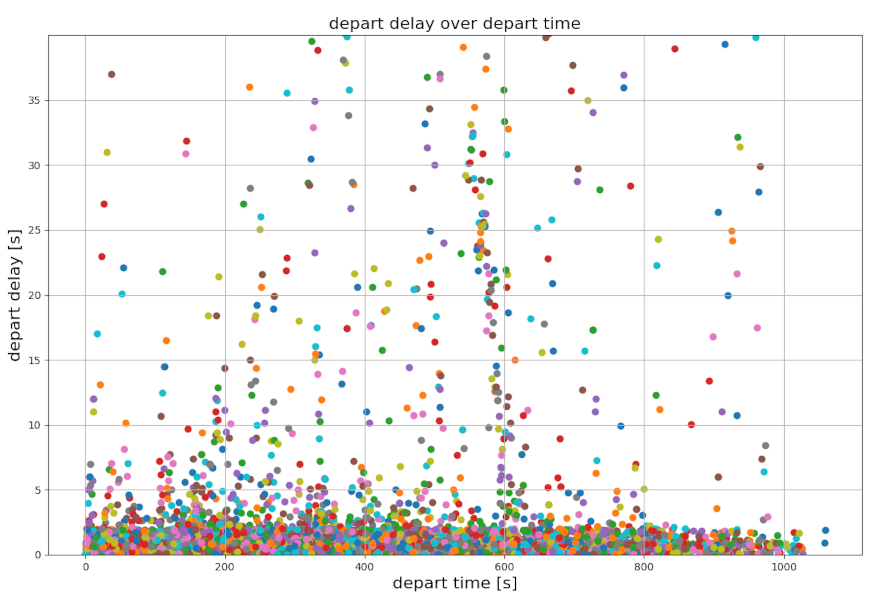
Depart delay over time from TripInfo data#
The plot is created out of TripInfo output data:
Call python tools/visualization/plotXMLAttributes.py -i id -x depart -y departDelay --scatterplot --xlabel "depart time [s]" --ylabel "depart delay [s]" --ylim 0,40 --xticks 0,1200,200,10 --yticks 0,40,5,10 --xgrid --ygrid --title "depart delay over depart time" --titlesize 16 tripInfo.xml
Time to collision over simulation time#
The plot is created from the output file of a SUMO simulation for which a global SSM device has been added. For this example, starting from the Bologna "acosta" scenario, the SUMO configuration file had been modified in order to compute time to collision:
<configuration xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="https://sumo.dlr.de/xsd/sumoConfiguration.xsd">
<device.ssm.deterministic value="true"/>
<device.ssm.file value="ssm.xml"/>
<device.ssm.measures value="TTC"/>
</configuration>
After the simulation has finished to run, a XML file ssm.xml has been produced. Using this file we can extract and plot the TTC values by using the command line:
python.exe .\plotXMLAttributes.py ssm.xml -x time --xlabel "Time [s]" -y value --ylabel "TTC [s]" -i ego --filter-ids bus_* --title "time to collision over simulation time" --scatterplot

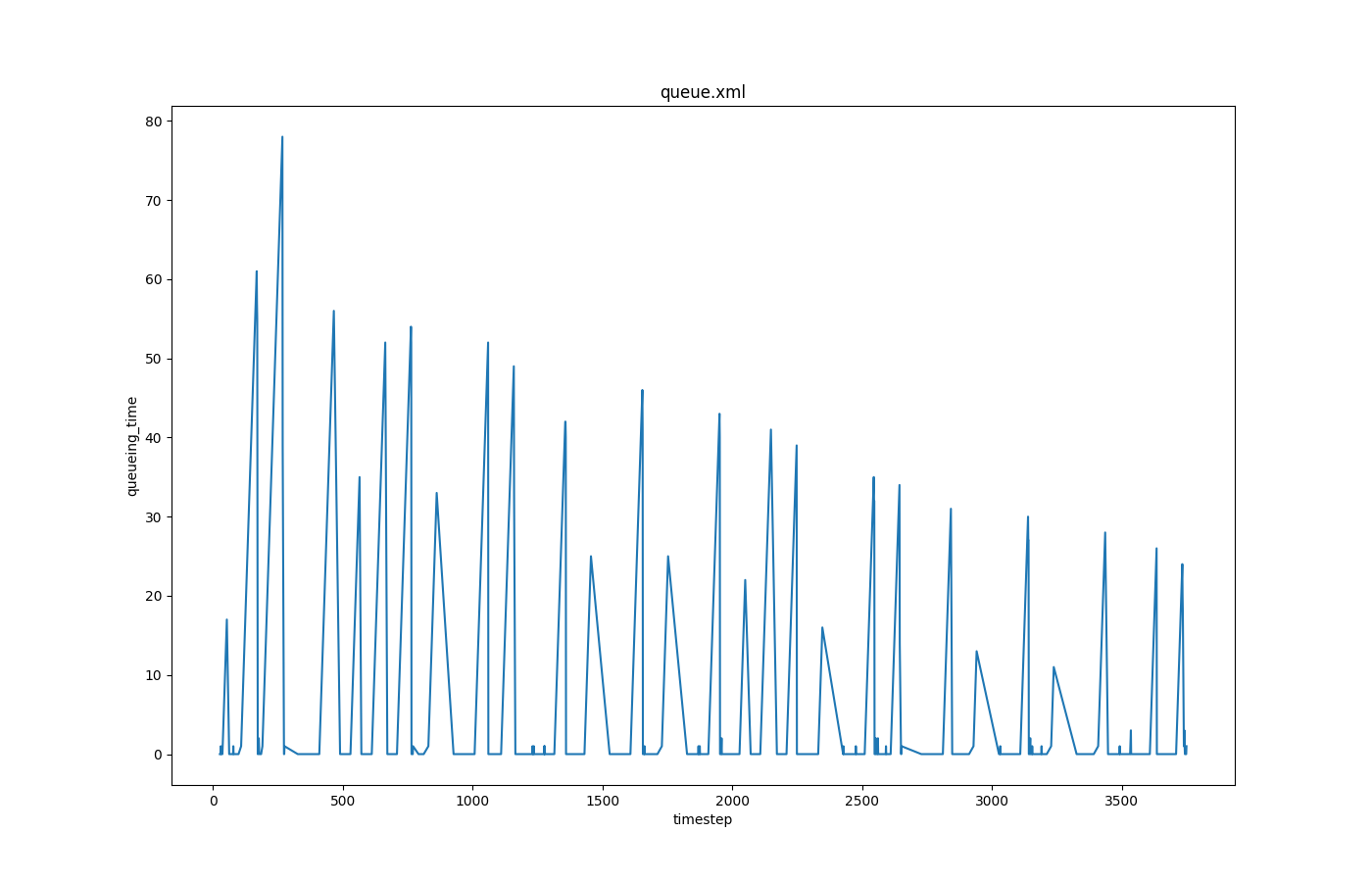
Queuing times over time#
Input is queue-output.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py -x timestep -y queueing_time -o queue.png queue.xml -i id --filter-ids 121_0
where -x is the attribute for the x axis; -y is the attribute for the y axis; -o is the output file name; -i is the filtered attribute name (lane id in this case); --filter-ids are the value(s) of the filtered attribute name (id = 121_0 in this case).
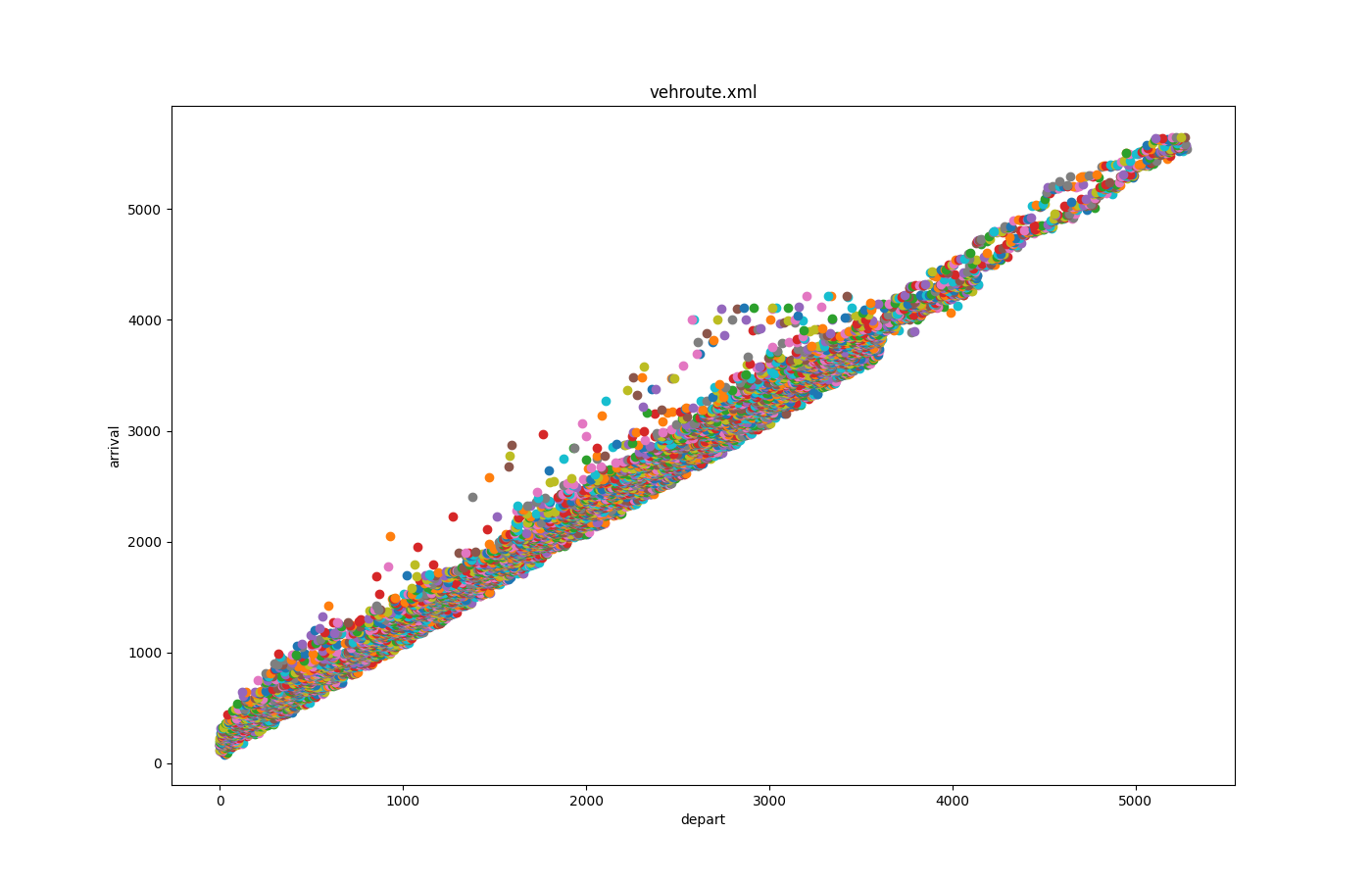
Departure times versus arrival times#
Input is vehroutes-output.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py -x depart -y arrival -o vehroute.png vehroute.xml --scatterplot
where -x is the attribute for the x axis; -y is the attribute for the y axis; -o is the output file name; --scatterplot is to make a scatter plot instead of a line plot.
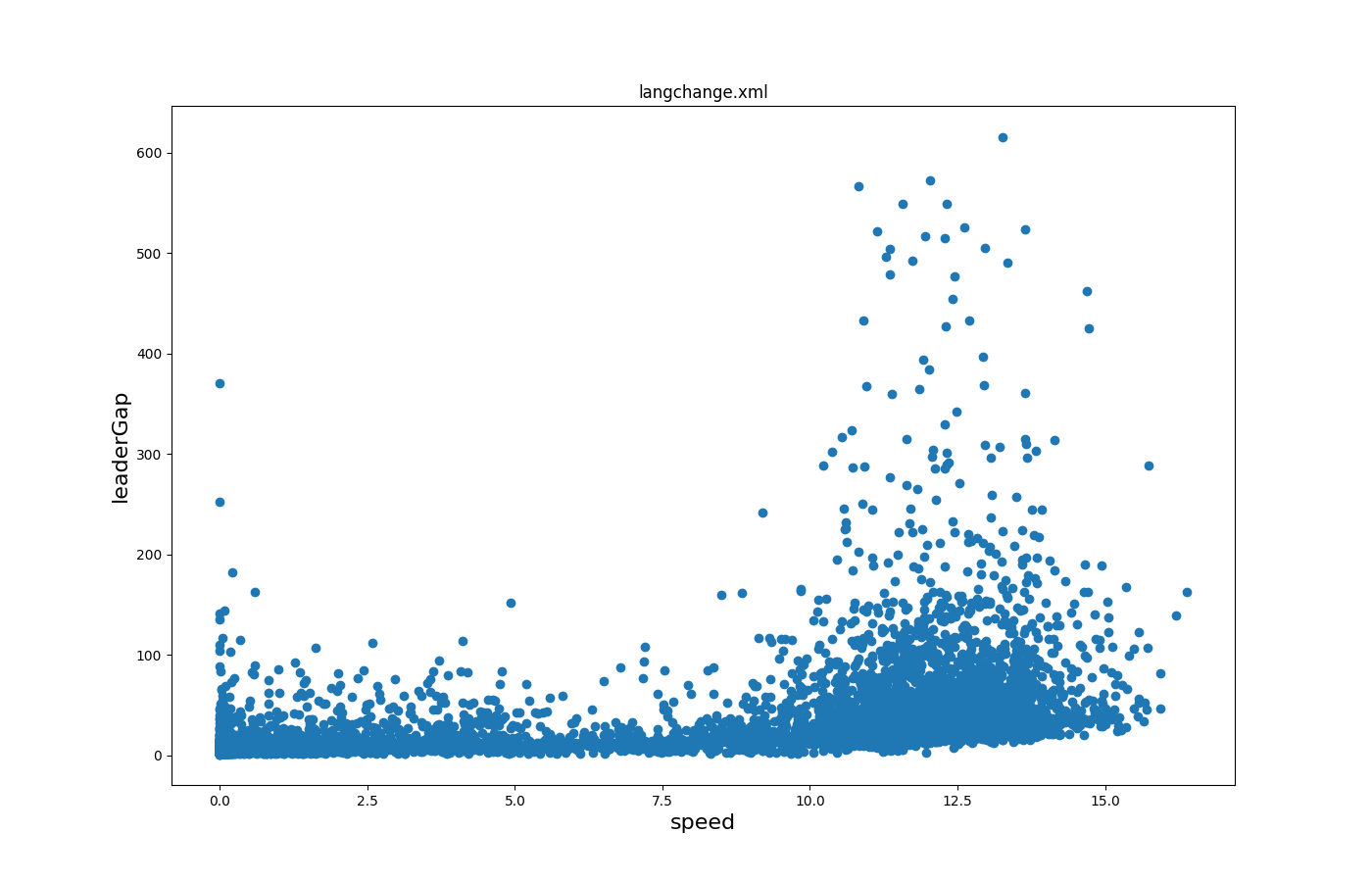
Leader gaps versus speeds#
Input is lanechange-output.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py -x speed -y leaderGap -o lc.png lanechange.xml -i reason --filter-ids speedGain
where -x is the attribute for the x axis; -y is the attribute for the y axis; -o is the output file name; -i is the filtered attribute name (reason for lane changing in this case); --filter-ids are the values of the filtered attribute name (reason = speedGain in this case).
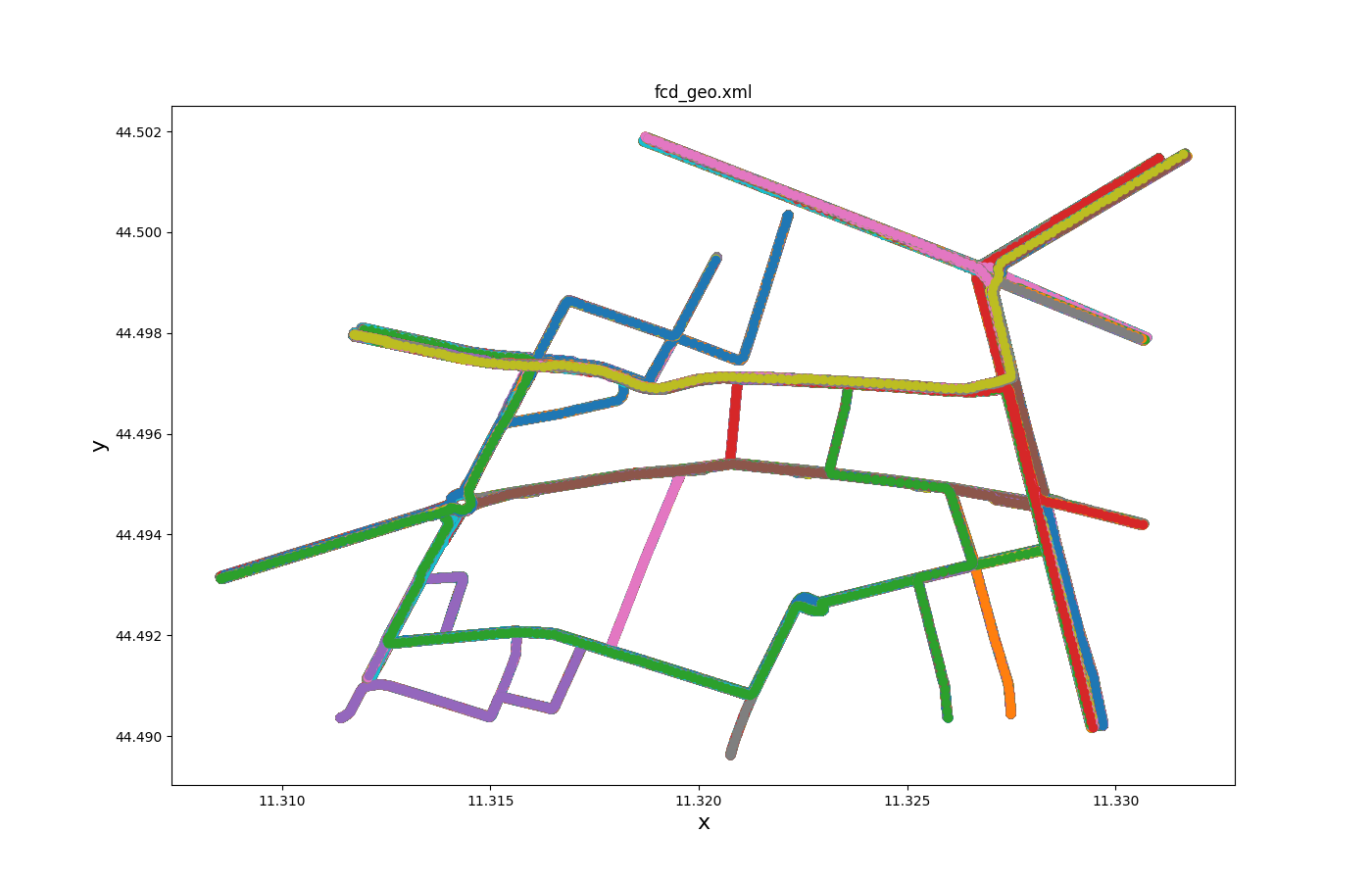
All trajectories over time 1#
Input is fcd_output.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py -x x -y y -o allXY_output.png fcd.xml --scatterplot
where -x is the attribute for the x axis; -y is the attribute for the y axis; -o is the output file name; --scatterplot is to make a scatter plot instead of a line plot..
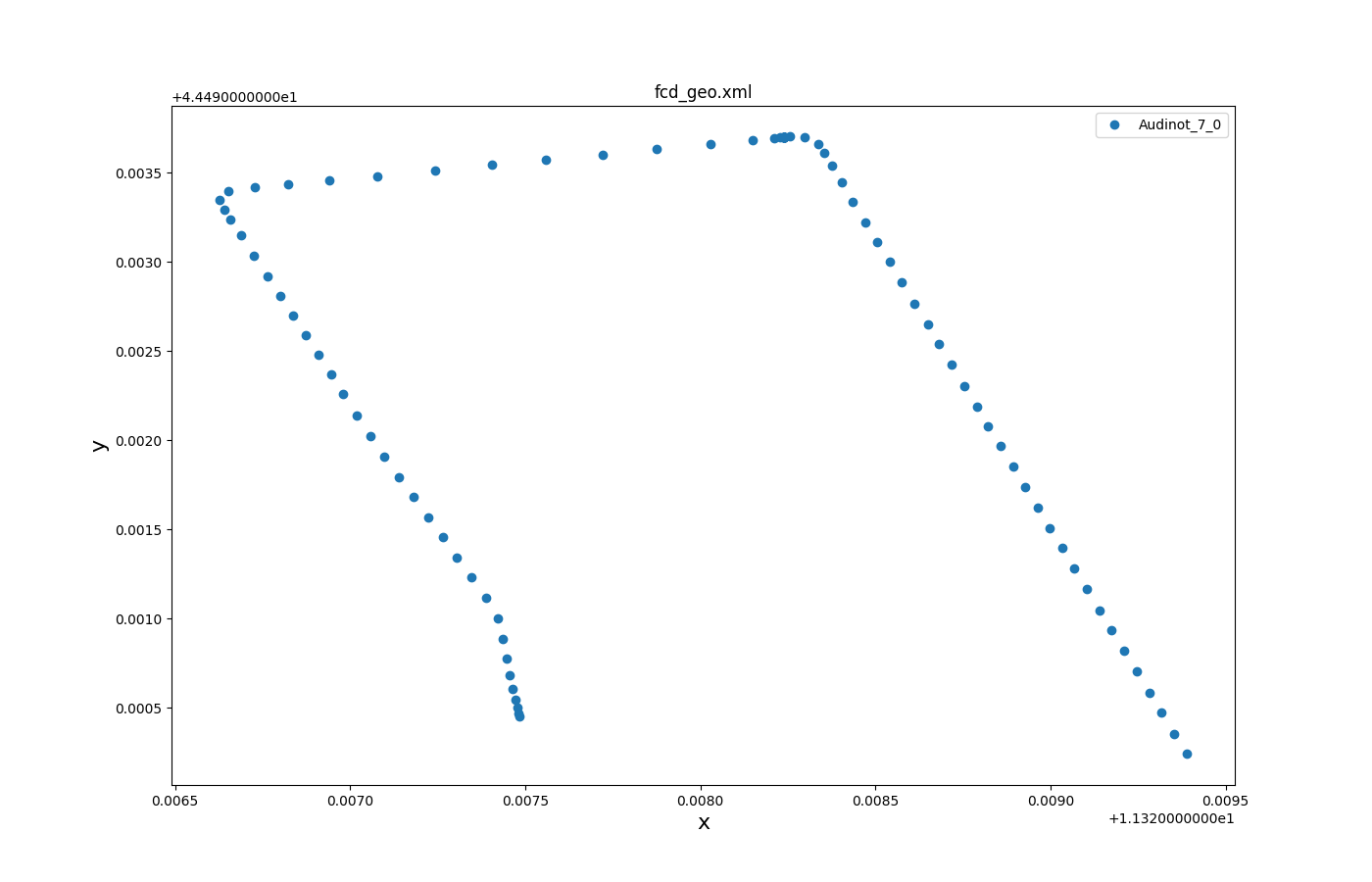
Selected trajectories over time 1#
Input is fcd_output.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py -x x -y y -o vehLocations_output.png fcd.xml -i id --filter-ids Audinot_7_0 --scatterplot --legend
where -x is the attribute for the x axis; -y is the attribute for the y axis; -o is the output file name; -i is the filtered attribute name (vehicle id in this case); --filter-ids are the values of the filtered attribute name (vehicle id = Audinot_7_0 in this case); --scatterplot is to make a scatter plot instead of a line plot; --legend is to show the legend.
Public transport schedule#
Note
The tool plotStops.py simplifies plotting such schedules
In this type of plot time is on the y-axis running from top to bottom. Input is route file of a public transport schedule where each vehicle is modelled individually.
A similar plot could also be generated from stop-output by using attribute started or ended (or started,ended) instead of until.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py route.rou.xml -x busStop -y until --ytime1 --legend --xticks-file stoplist.txt --invert-yaxis --marker o
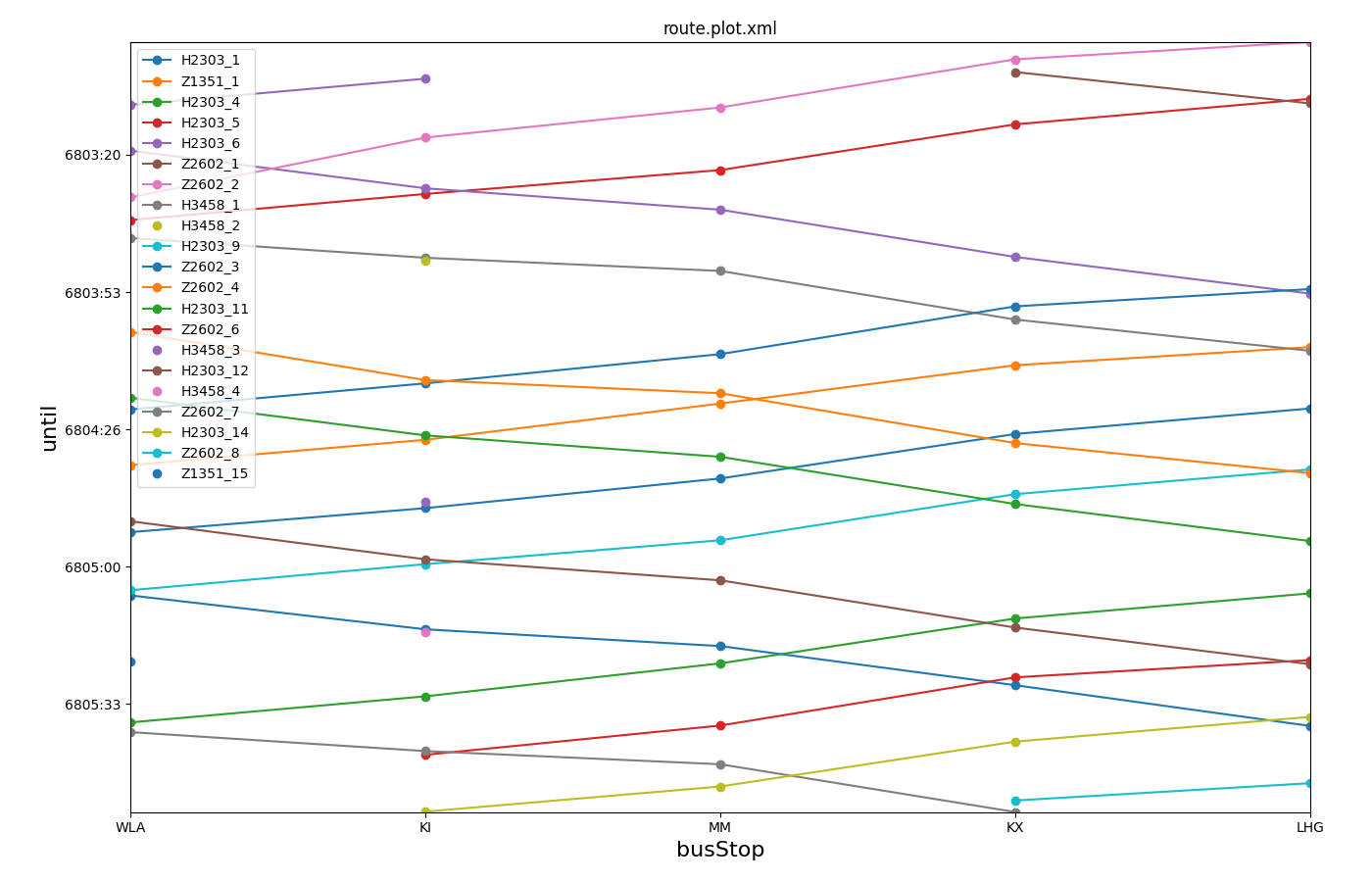
The file stoplist.txt is used to define the ordering of the stops (corresponding to their ordering along a transport line) and is shown below.
In order to group busStops that belong to different tracks of the same train station, they were named with a common suffix in their id and the stoplist.txt file uses wildcards (*) to match them.
*WLA
*KI
*MM
*KX
*LHG
Note
The main advantage of plotStops.py is creating a stoplist.txt file automatically.
Note
When plotting stops from a route file that also defines <vType> elements, then the option --idelem must be used to declare where the id attribute must be loaded from (i.e. --idelem trip).
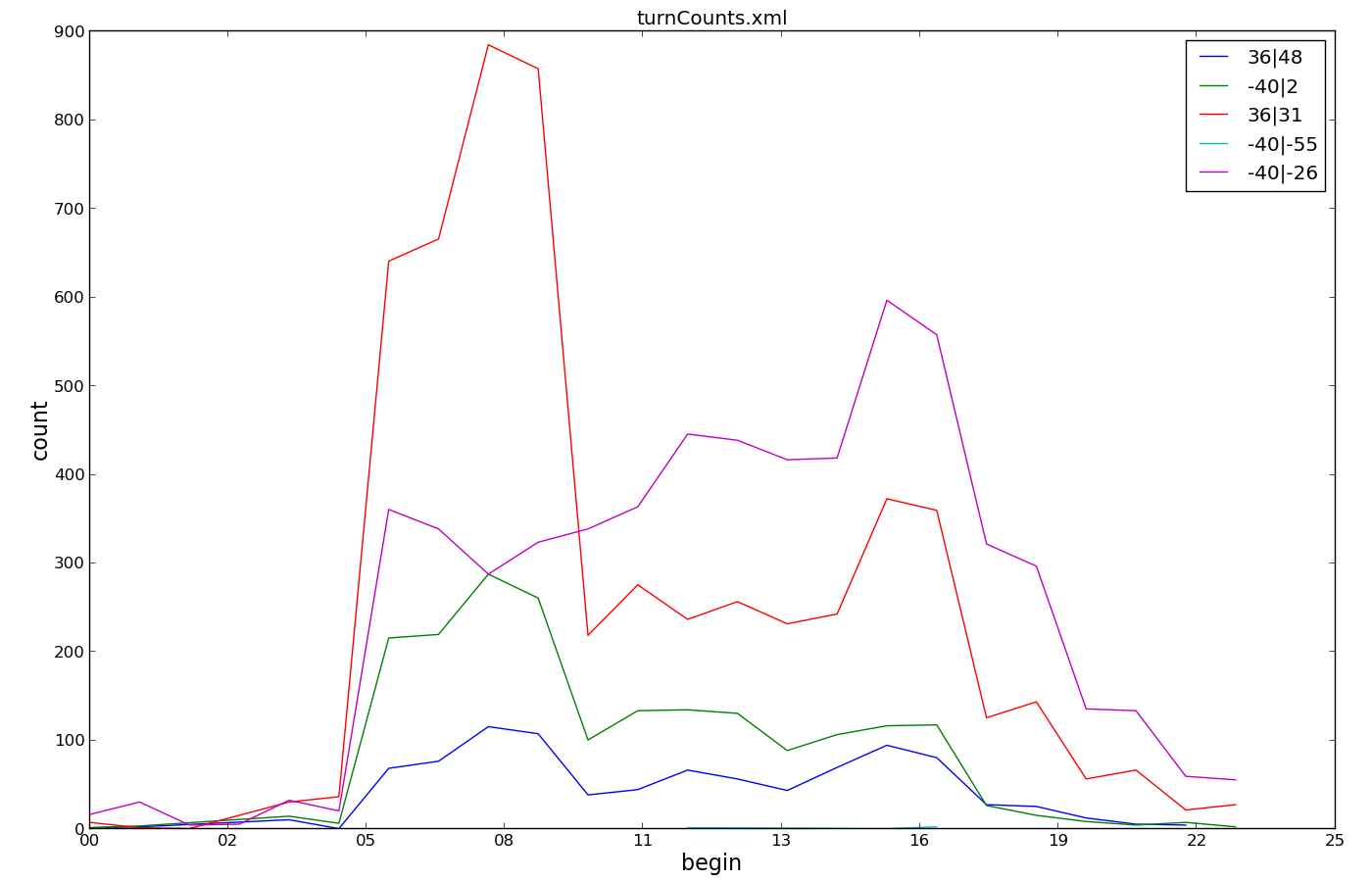
Turn-counts over time#
This plot uses an attribute list for the value id (-i from,to) to reflect the fact that a turning relation is uniquely identified by the combination of two attributes. It also demonstrates flexible filtering to show all traffic that passes over edge -40 or edge 36.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py turnCounts.xml -i from,to -x begin -y count --xtime0 --legend --filter-ids="-40|*,36|*"
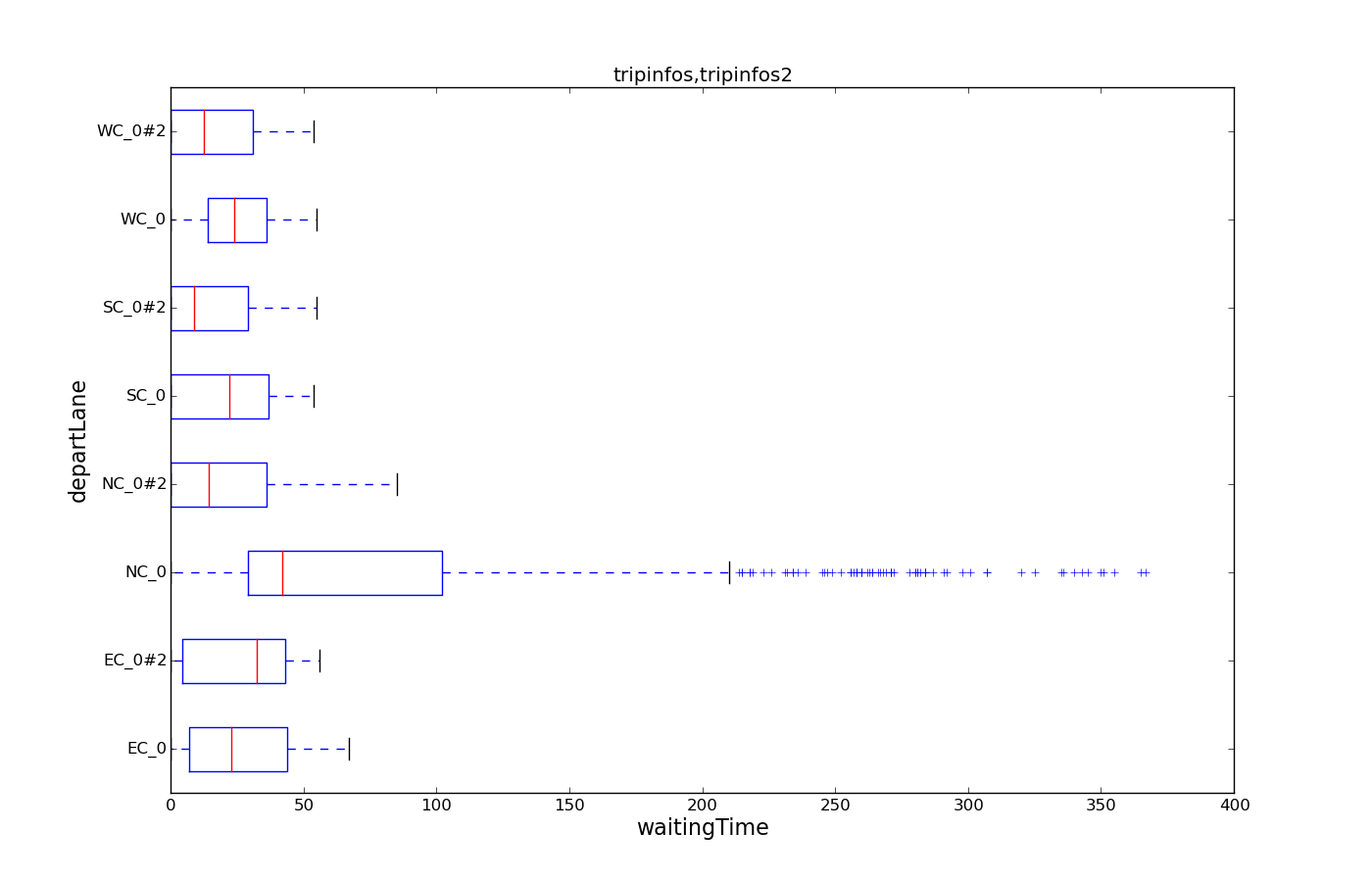
Boxplot: waiting time by departLane#
This plot demonstrates box-plotting for a single attribute (waitingTime). Optionally split by category (departLane). The call uses tripinfo-output from two different simulation runs as it's input.
Call to generate the plot:
python tools/visualization/plotXMLAttributes.py tripinfos.xml tripinfos2.xml -x waitingTime -y @BOX -i departLane --show
Note
By swapping x-attribute and y-attribute the orientation of the boxplot can be changed from horizontal to vertical
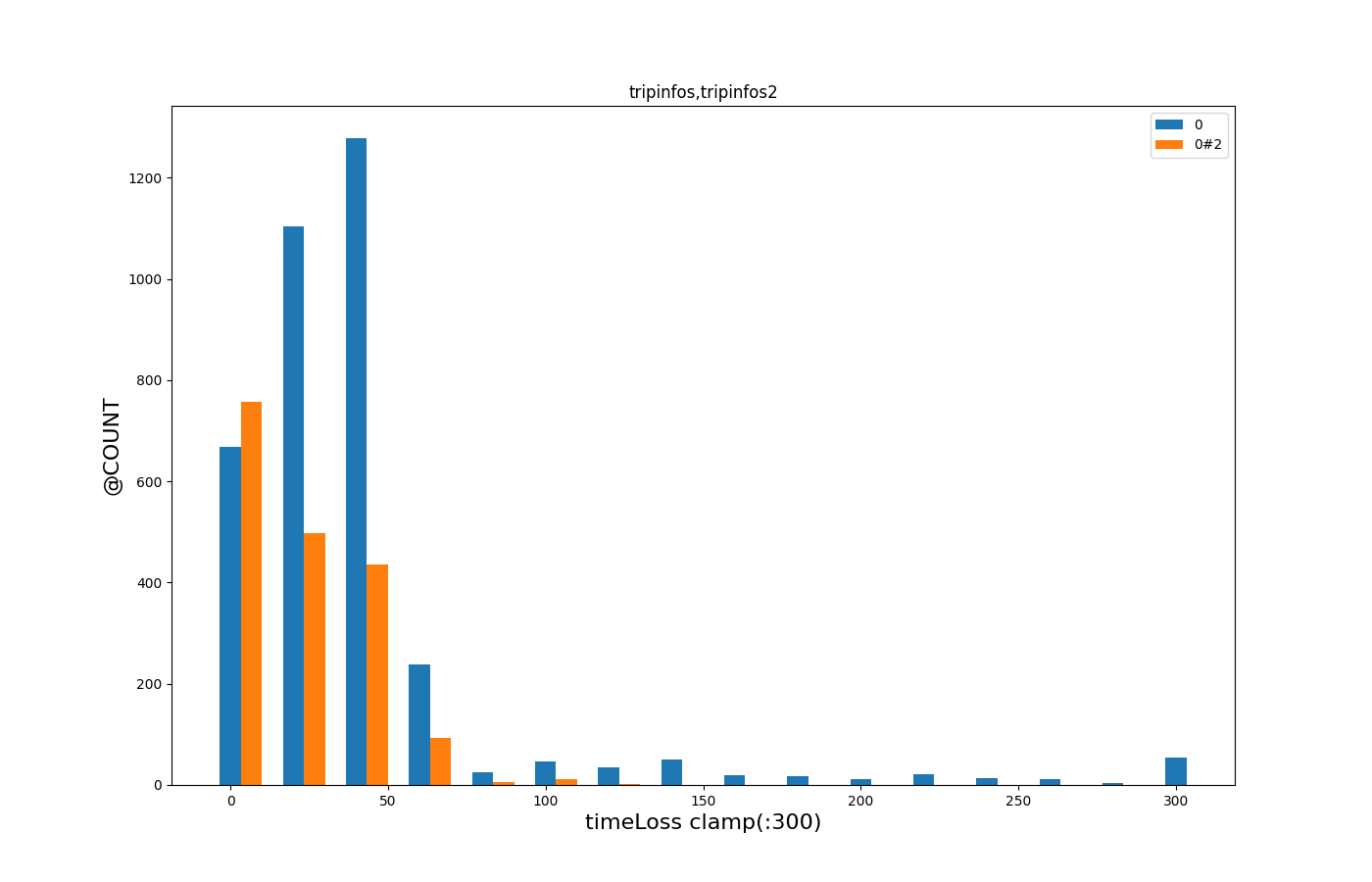
Histogram of timeLoss#
This plot demonstrates the use of --barplot binning and @COUNT to create a histogram of timeLoss values from two simulation runs.
It also shows how to clamp data to the upper range of 300.
Call to generate the plot:
plotXMLAttributes.py tripinfos.xml tripinfos2.xml -x timeLoss -y @COUNT -i @NONE --legend --barplot --xbin 20 --xclamp :300
Caution
It is important to set -i @NONE to ensure that the timeLoss values are aggregated by file rather than by vehicle id.
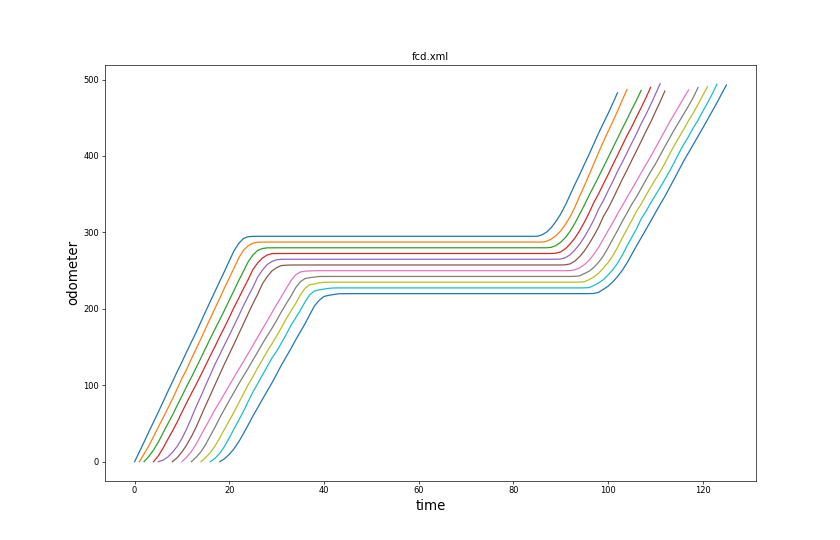
Time-Space-Plot#
This plot demonstrates a common use-case in traffic simulation: Mapping vehicle positions to a single dimension (i.e. distance driven from a common point) and plotting that distance value over time with one continuous line per vehicle. This kind of plot reveals how disturbances in traffic flow move in space and time through the intuitive impressions of slope and line density. The source data for this kind of plot is typically FCD-Output and there are different ways to obtain the one dimensional position for the vehicles:
- use x (or y) coordinate in case the road is aligned with the coordinate system (i.e. in a synthetic scenario). The command is
plotXMLAttributes.py fcd.xml -x time -y x - use the total distance driven since the vehicle started (i.e. when all vehicles depart at the same location). Requires SUMO option to enable FCD attribute 'odometer': --fcd-output.attributes odometer (or --fcd-output.attributes all). The command is
plotXMLAttributes.py fcd.xml -x time -y odometer - use a sumo network where roads are part of linear reference scheme (kilometrage). Requires SUMO option to enable FCD attribute 'distance': --fcd-output.attributes distance (or --fcd-output.attributes all). The command is
plotXMLAttributes.py fcd.xml -x time -y distance
plot_trajectories.py#
Create plot of all trajectories obtained from a file generated through --fcd-output. This tool in particular is located in <SUMO_HOME>/tools.
Example use:
python tools/plot_trajectories.py fcd.xml -t td -o plot.png -s
The option -t (--trajectory-type) supports different attributes that can be plotted against each other. The argument is a two-letter code with each letter encoding an attribute that is derived from the fcd input.
Note
plot_trajectories.py is similar to plotXMLAttributes.py but specialized for fcd-output. It supports derived attributes that are not present in the loaded data (driven distance) and also allows for more filtering (--filter-route, --filter-edges).
Available Attributes#
- t: Time in s
- d: Distance driven (starts with 0 at the first fcd datapoint for each vehicle). Distance is computed based on speed using Euler-integration. Set option --ballistic for ballistic integration.
- a: Acceleration
- s: Speed (m/s)
- i: Vehicle angle (navigational degrees)
- x: X-Position in m
- y: Y-Position in m
- k: Kilometrage (requires --fcd-output.distance)
- g: gap to leader (requires --fcd-output.max-leader-distance)
Examples Trajectory Types#
- td: time vs distance
- ts: time vs speed
- ta: time vs acceleration
- ds: distance vs speed
- da: distance vs acceleration
- xy: Spatial plot of driving path
- kt: kilometrage vs time (combine with option --invert-yaxis to get a classic railway diagram).
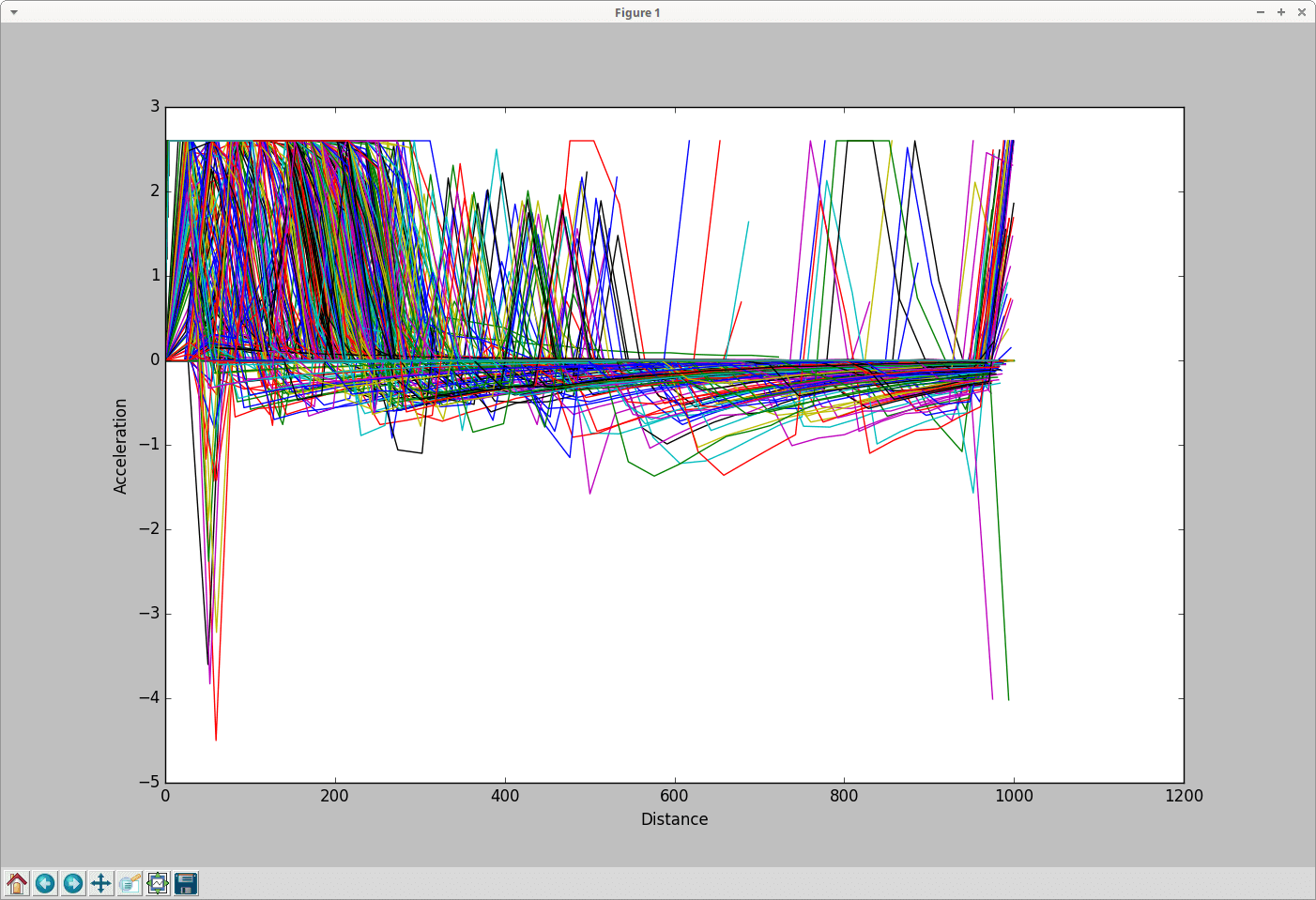
Accelerations versus distances#
Input is fcd-output.
Call to generate the plot:
python tools/plot_trajectories.py -t da -o Plot_trajectories.png fcd.xml
where -t is the aforementioned trajectory type; -o is the output file name.
All trajectories over time 2#
Input is fcd-output.
Call to generate the plot:
python tools/plot_trajectories.py -t xy -o allLocations_output.png fcd.xml
where -t is the aforementioned trajectory type; -o is the output file name.
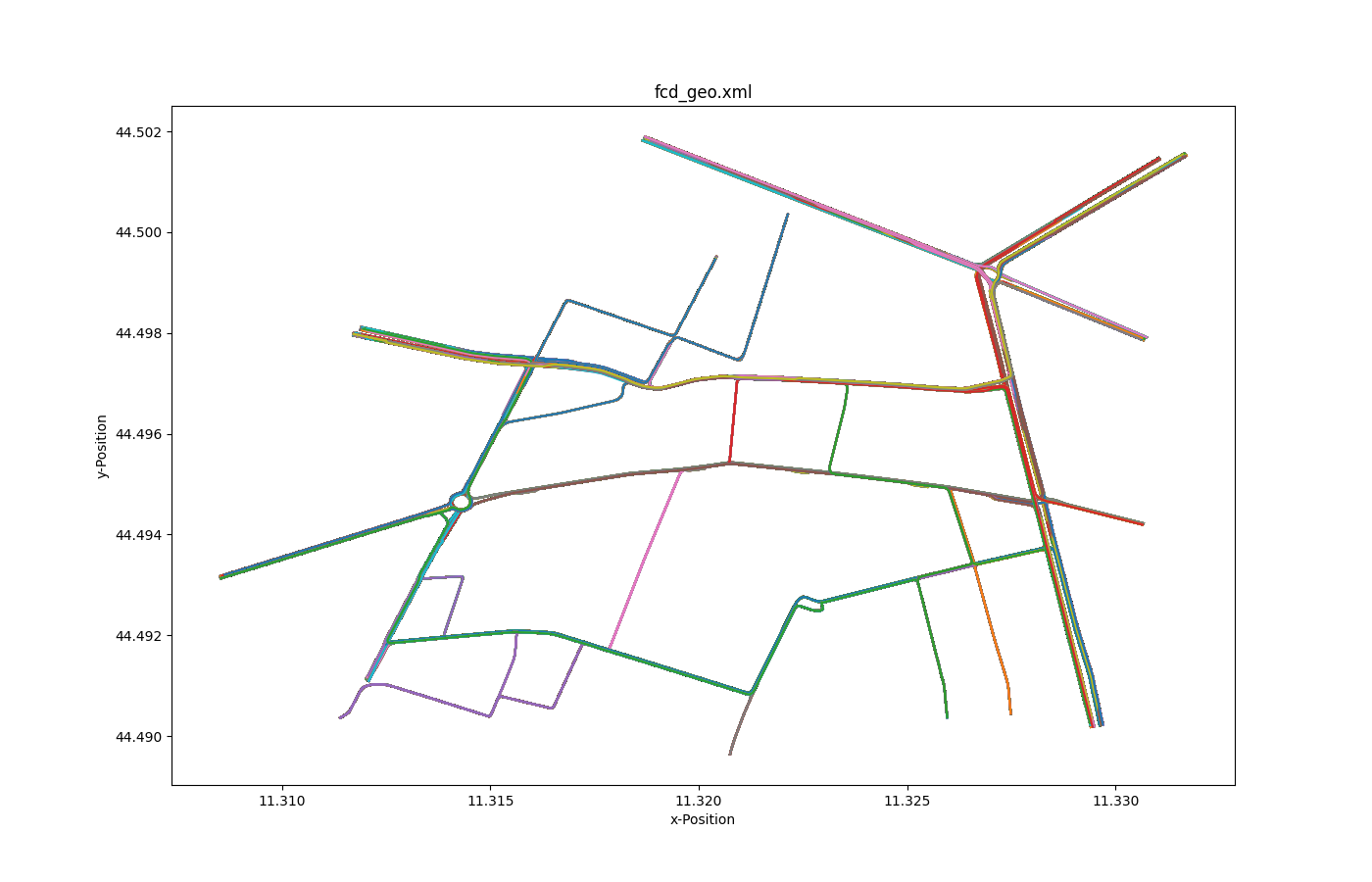
Selected trajectories over time 2#
Input is fcd-output.
Call to generate the plot:
python tools/plot_trajectories.py -t xy -o selectXY_output.png fcd.xml --filter-ids Audinot_7_0
where -t is the aforementioned trajectory type; -o is the output file name;--filter-ids are the value(s) of the filtered attributes (id = Audinot_7_0 in this case).
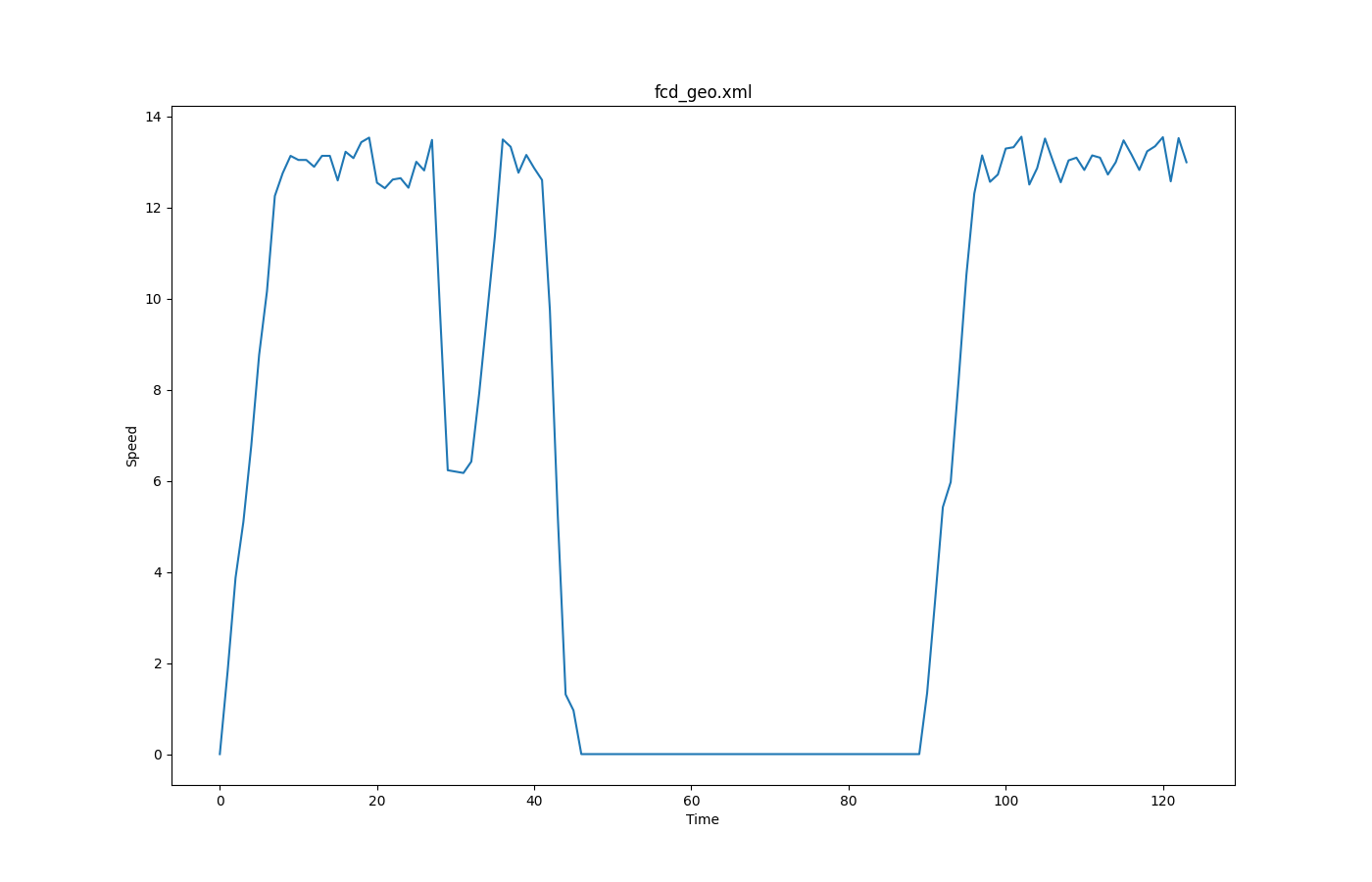
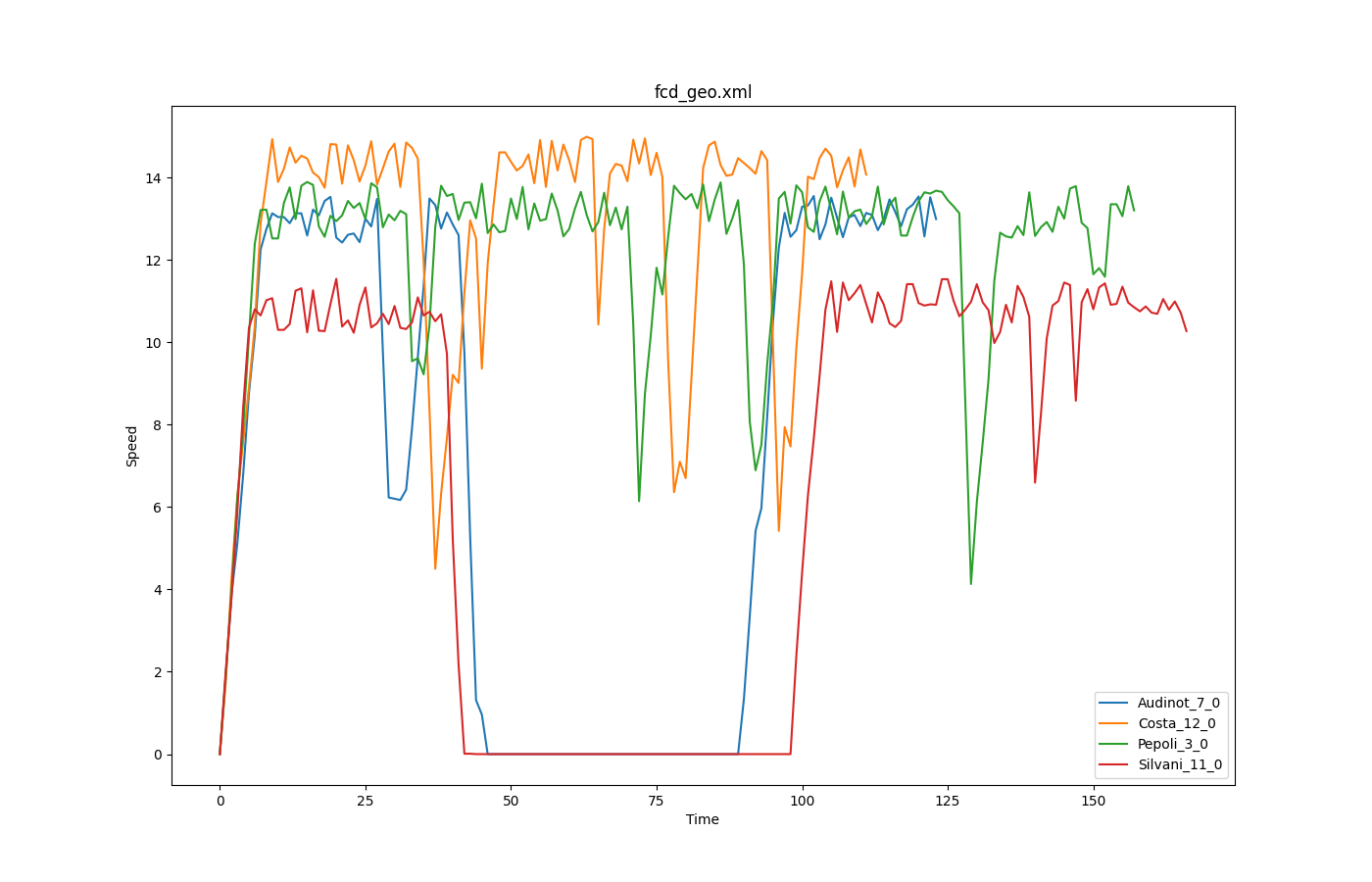
FCD based speeds over time#
Input is fcd-output.
Call to generate the plot:
python tools/plot_trajectories.py -t ts -o timeSpeed_output.png fcd.xml --filter-ids Audinot_7_0,Costa_12_0,Pepoli_3_0,Silvani_11_0,XXI_APRILE_7_0 --legend
where -t is the aforementioned trajectory type; -o is the output file name; --filter-ids are the value(s) of the filtered attributes (id in [Audinot_7_0, Costa_12_0, Pepoli_3_0, Silvani_11_0, XXI_APRILE_7_0] in this case); --legend is to show the legend
Interactive Plot#
When option -s is set, a interactive plot is opened that allows identifying vehicles by clicking on the respective line (vehicle ids is printed in the console).
Filtering#
Option --filter-route EDGE1,EDGE2,... allows restricting the plot to all trajectories that contain the given set of edges.
Option --filter-ids ID1,ID2,... allows restricting the plot to the given vehicle ids
plot_net_dump.py#
plot_net_dump.py shows a network, where the network edges' colors and width are set in dependence to defined edge attributes. The edge weights are read from "edgedumps" - edgelane traffic, edgelane emissions, or edgelane noise.
| Output | Command |
|---|---|
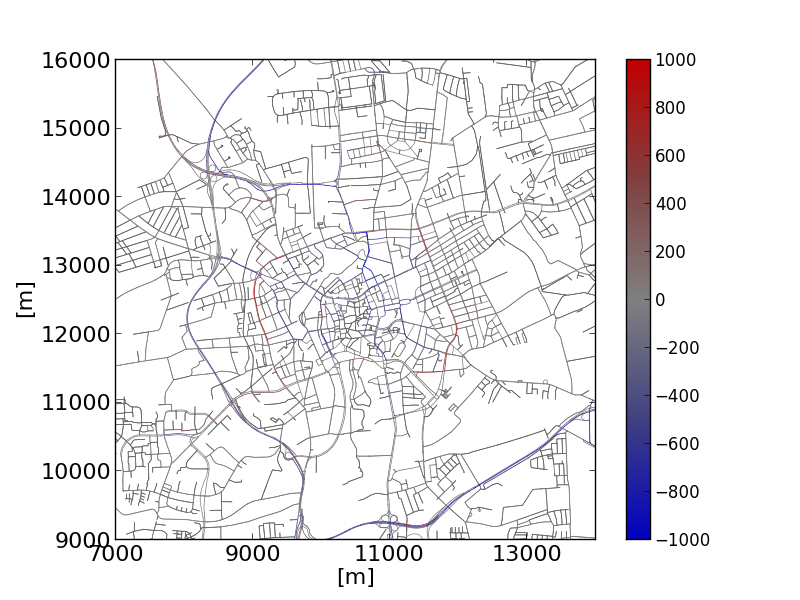 |
python plot_net_dump.py -v -n bs.net.xml \--xticks 7000,14001,2000,16 --yticks 9000,16001,1000,16 \--measures entered,entered --xlabel [m] --ylabel [m] \--default-width 1 -i base-jr.xml,base-jr.xml \--xlim 7000,14000 --ylim 9000,16000 -\--default-width .5 --default-color #606060 \--min-color-value -1000 --max-color-value 1000 \--max-width-value 1000 --min-width-value -1000 \--max-width 3 --min-width .5 \--colormap "#0:#0000c0,.25:#404080,.5:#808080,.75:#804040,1:#c00000"It shows the shift in traffic in the city of Brunswick, Tuesday-Thursday week type after establishing an environmental zone. |
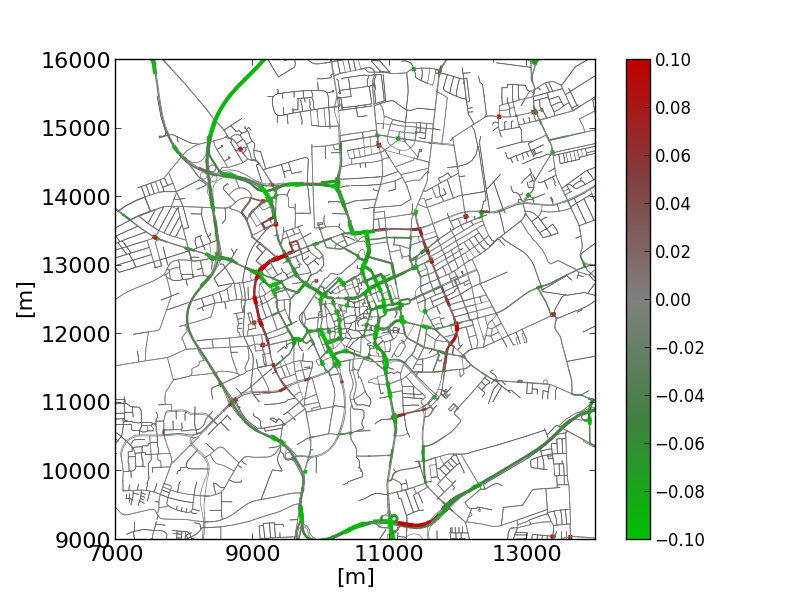 |
python plot_net_dump.py -v -n bs.net.xml \--xticks 7000,14001,2000,16 --yticks 9000,16001,1000,16 \--measures NOx_normed,NOx_normed --xlabel [m] --ylabel [m] \--default-width 1 -i HBEFA_base-jr.xml,HBEFA_base-jr.xml \--xlim 7000,14000 --ylim 9000,16000 \--default-width .5 --default-color #606060 \--min-color-value -.1 --max-color-value .1 \--max-width-value .1 --max-width 3 --min-width .5 \--colormap "#0:#00c000,.25:#408040,.5:#808080,.75:#804040,1:#c00000"Showing the according changes in NOx emissions. |
- both, --dump-inputs <FILE>,<FILE> as well as --measures <STRING>,<STRING> expect two entries being divided by a ','. The first is used for the edges' color, the second for their widths. But you may simply skip one entry. Then, the default values are used.
- dump-files cover usually more than one interval. To generate an extra output file for each interval, use the string '%s' as part of the output filename (this part will be replaced with the corresponding begin time).
Caution
If two input files are given they must cover the same time intervals or no data will be plotted.
Options
Here the most important options are listed. Use --help to see all options.
| Option | Description |
|---|---|
| -n <FILE> --net <FILE> |
Defines the network to read |
| -i <FILE>,<FILE> --dump-inputs <FILE>,<FILE> |
Defines the dump-output files to use as input |
| -m <STRING>,<STRING> --measures <STRING>,<STRING> |
Define which measure to plot;default: speed,entered |
| -w <FLOAT> --default-width <FLOAT> |
Defines the default edge width; default: .1 |
| -c <COLOR> --default-color <COLOR> |
Defines the default edge color |
| --min-width <FLOAT> | Defines the minimum edge width; default: .5 |
| --max-width <FLOAT> | Defines the maximumedge width; default: 3 |
| --log-colors | If set, colors are log-scaled |
| --log-widths | If set, widths are log-scaled |
| --min-color-value <FLOAT> | If set, defines the minimum edge color value |
| --max-color-value <FLOAT> | If set, defines the maximum edge color value |
| --min-width-value <FLOAT> | If set, defines the minimum edge width value |
| --max-width-value <FLOAT> | If set, defines the maximum edge width value |
| -v --verbose |
If set, the progress is printed on the screen |
| --internal | If set, internal edges (of junctions) are included to the generated shapes. |
plot_net_selection.py#
plot_net_selection.py reads a road network and a selection file as written by sumo-gui. It plots the road network, choosing a different color and width for the edges which are within the selection (all edge with at least one lane in the selection).
| Output | Command |
|---|---|
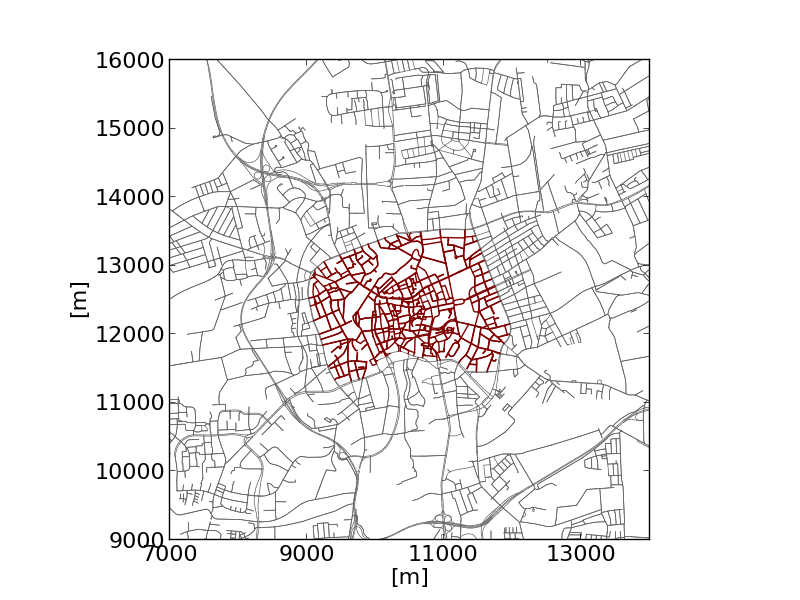 |
python plot_net_selection.py -n bs.net.xml \--xlim 7000,14000 --ylim 9000,16000 \-i selection_environmental_zone.txt \--xlabel [m] --ylabel [m] \--xticks 7000,14001,2000,16 --yticks 9000,16001,1000,16 \--selected-width 1 --edge-width .5 -o selected_ez.png \--edge-color #606060 --selected-color #800000The example shows the selection of an "environmental zone". |
Options
| Option | Description |
|---|---|
| -n <FILE> --net <FILE> |
Defines the network to read |
| -i <FILE> --selection <FILE> |
Defines selection file to read |
| --selected-width <FLOAT> | Defines the width for selected edges;default: 1 |
| --selected-color <COLOR> | Defines the color for selected edges; default: r (red) |
| --edge-width <FLOAT> | Defines the default edge width; default: .2 |
| --edge-color <COLOR> | Defines the default edge color; default: #606060 |
| -v --verbose |
If set, the progress is printed on the screen |
plot_net_speeds.py#
plot_net_speeds.py reads a road network and plots it using the allowed speeds to color the edges. It is rather an example for using measures read from the network file.
| Output | Command |
|---|---|
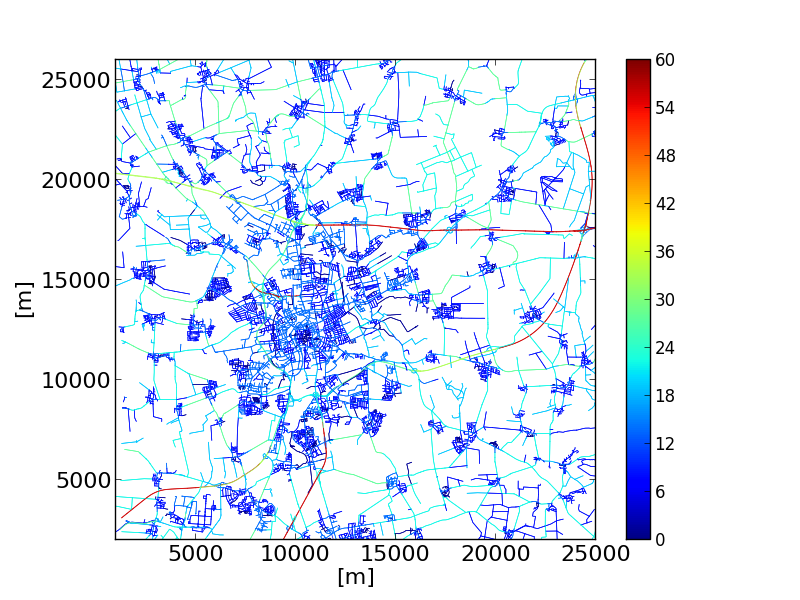 |
python plot_speeds.py -n bs.net.xml --xlim 1000,25000 \--ylim 2000,26000 --edge-width .5 -o speeds2.png \--minV 0 --maxV 60 --xticks 16 --yticks 16 \--xlabel [m] --ylabel [m] --xlabelsize 16 --ylabelsize 16 \--colormap jetThe example colors the streets in Brunswick, Germany by their maximum allowed speed. |
Options
| Option | Description |
|---|---|
| -n <FILE> --net <FILE> |
Defines the network to read |
| --edge-width <FLOAT> | Defines the default edge width; default: .2 |
| --edge-color <COLOR> | Defines the default edge color; default: #606060 |
| --minV <FLOAT> | Define the minimum value boundary |
| --maxV <FLOAT> | Define the maximum value boundary |
| -v --verbose |
If set, the script says what it's doing |
plot_net_trafficLights.py#
plot_net_trafficLights.py reads a road network and plots it and additionally adds dots/markers at the position of traffic lights that are part of the net.
| Output | Command |
|---|---|
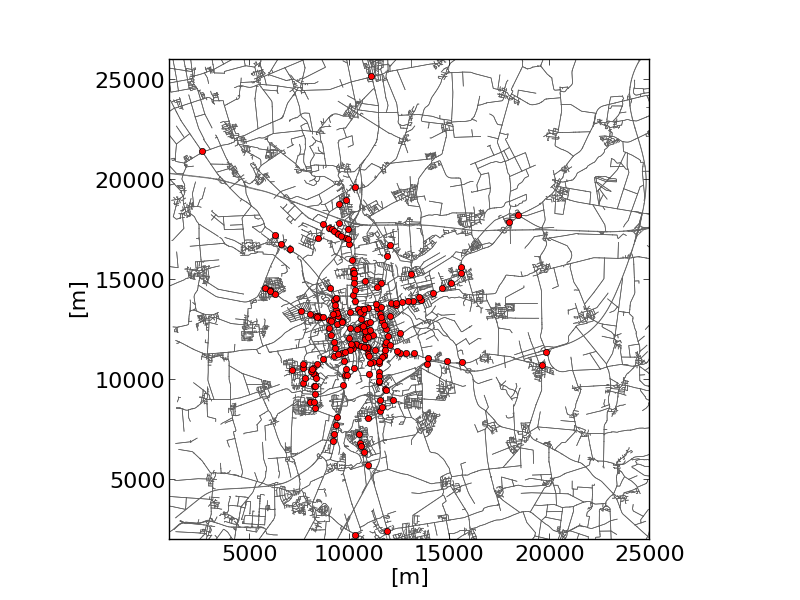 |
python plot_trafficLights.py -n bs.net.xml \--xlim 1000,25000 --ylim 2000,26000 --edge-width .5 \--xticks 16 --yticks 16 --xlabel [m] --ylabel [m] \--xlabelsize 16 --ylabelsize 16 --width 5 \--edge-color #606060The example shows the traffic lights in Brunswick. |
Options
| Option | Description |
|---|---|
| -n <FILE> --net <FILE> |
Defines the network to read |
| --edge-width <FLOAT> | Defines the default edge width; default: .2 |
| --edge-color <COLOR> | Defines the default edge color; default: #606060 |
| --minV <FLOAT> | Define the minimum value boundary |
| --maxV <FLOAT> | Define the maximum value boundary |
| -v --verbose |
If set, the script says what it's doing |
plot_summary.py#
plot_summary.py reads one or multiple summary-files and plots a selected measure (attribute of the read summary-files). The measure is visualised as a time line along the simulation time.
| Output | Command |
|---|---|
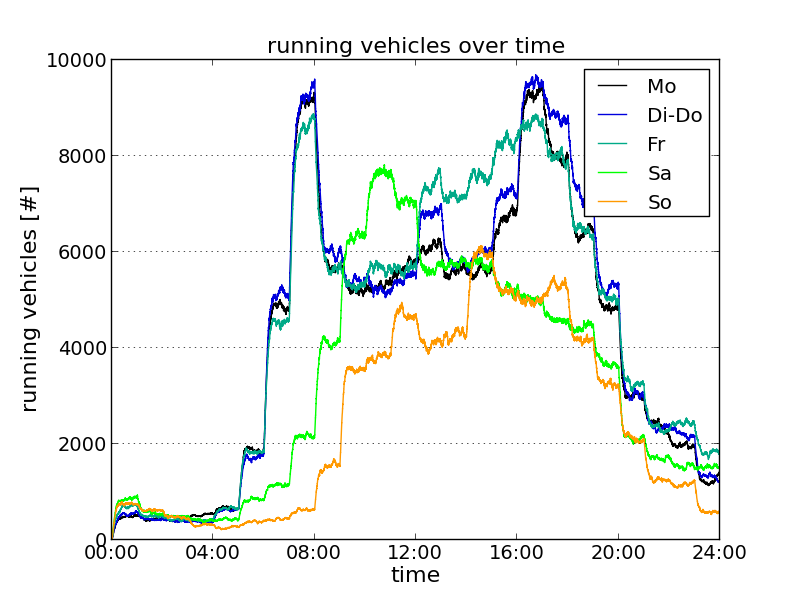 |
python plot_summary.py-i mo.xml,dido.xml,fr.xml,sa.xml,so.xml \-l Mo,Di-Do,Fr,Sa,So --xlim 0,86400 --ylim 0,10000-o sumodocs/summary_running.png --yticks 0,10001,2000,14 \--xticks 0,86401,14400,14 --xtime1 --ygrid \--ylabel "running vehicles [#]" --xlabel "time" \--title "running vehicles over time" --adjust .14,.1The example shows the numbers of vehicles running in a large-scale scenario of the city of Brunswick over the day for the standard week day classes. "mo.xml", "dido.xml", "fr.xml", "sa.xml", and "so.xml" are summary-files resulting from simulations of the weekday-types Monday, Tuesday-Thursday, Friday, Saturday, and Sunday, respectively. |
Options
| Option | Description |
|---|---|
| -i <FILE>[,<FILE>]* --summary-inputs <FILE>[,<FILE>]* |
Defines the summary-file(s) to read |
| -m <STRING> --measure <STRING> |
Defines the measure to read from the summary file; default: running |
| -v --verbose |
If set, the progress is printed on the screen |
| --dpi <FLOAT> | Define dpi resolution for figures; default: None |
plot_tripinfo_distributions.py#
plot_tripinfo_distributions.py reads one or multiple tripinfo-files and plots a selected measure (attribute of the read tripinfo-files). The measure is visualised as vertical bars that represent the numbers of occurrences of the measure (vehicles) that fall into a bin.
| Output | Command |
|---|---|
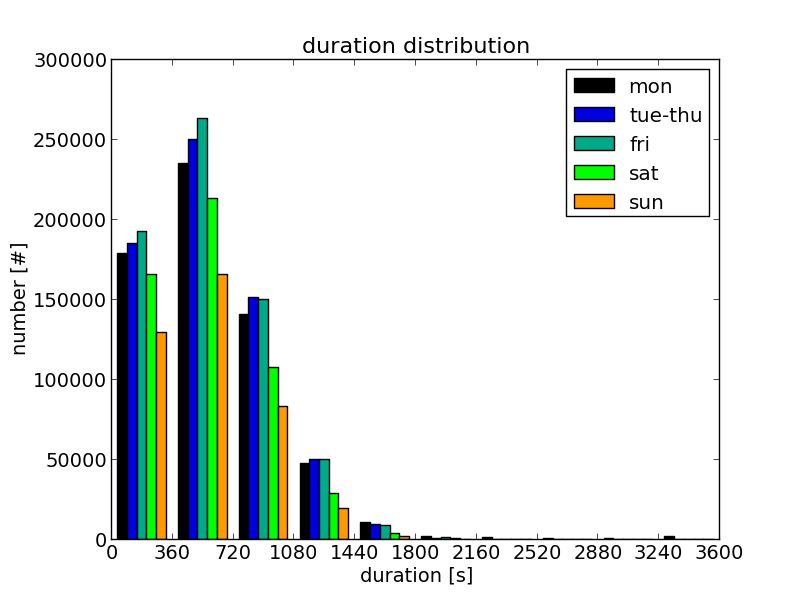 |
python plot_tripinfo_distributions.py \-i mo.xml,dido.xml,fr.xml,sa.xml,so.xml \-o tripinfo_distribution_duration.png -v -m duration \--minV 0 --maxV 3600 --bins 10 --xticks 0,3601,360,14 \--xlabel "duration [s]" --ylabel "number [#]" \--title "duration distribution" \--yticks 14 --xlabelsize 14 --ylabelsize 14 --titlesize 16 \-l mon,tue-thu,fri,sat,sun --adjust .14,.1 --xlim 0,3600The example shows the travel time distribution for the vehicles of different week day classes (Braunschweig scenario). "mo.xml", "dido.xml", "fr.xml", "sa.xml", and "so.xml" are tripinfo-files resulting from simulations of the weekday-types Monday, Tuesday-Thursday, Friday, Saturday, and Sunday, respectively. |
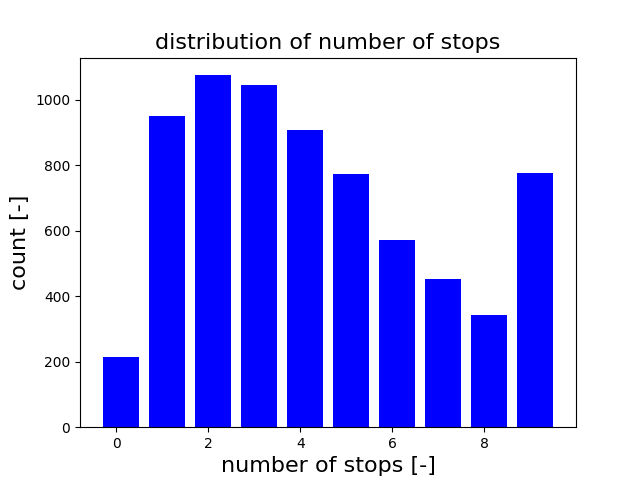 |
python plot_tripinfo_distributions.py -i tripinfo.xml -o stopCountDist.png \--measure waitingCount --bins 10 --maxV 10 \--xlabel "number of stops [-]" --ylabel "count [-]" \--title "distribution of number of stops" --colors blue -b --no-legendThe example shows the distribution of stops the vehicles had to make during their trip. Vehicles with more than 9 stops are added to the last bin of the histogram. |
Options
| Option | Description |
|---|---|
| -i <FILE>[,<FILE>]* --tripinfos-inputs <FILE>[,<FILE>]* |
Defines the summary-file(s) to read |
| -m <STRING> --measure <STRING> |
Defines the measure to read from the summary file |
| -v --verbose |
If set, the progress is printed on the screen |
| --bins <INT> | The number of bins to divide the values into |
| --norm <FLOAT> | Defines a number by which read values are divided; default: 1.0 |
| --minV <FLOAT> | The minimum value; if set, read values that are lower than this value are set to this value |
| --maxV <FLOAT> | The maximum value; if set, read values that are higher than this value are set to this value |
plot_csv_timeline.py#
plot_csv_timeline.py reads a .csv file and plots columns selected using the --columns <INT>[,<INT>]* option. The values are visualised as lines.
| Output | Command |
|---|---|
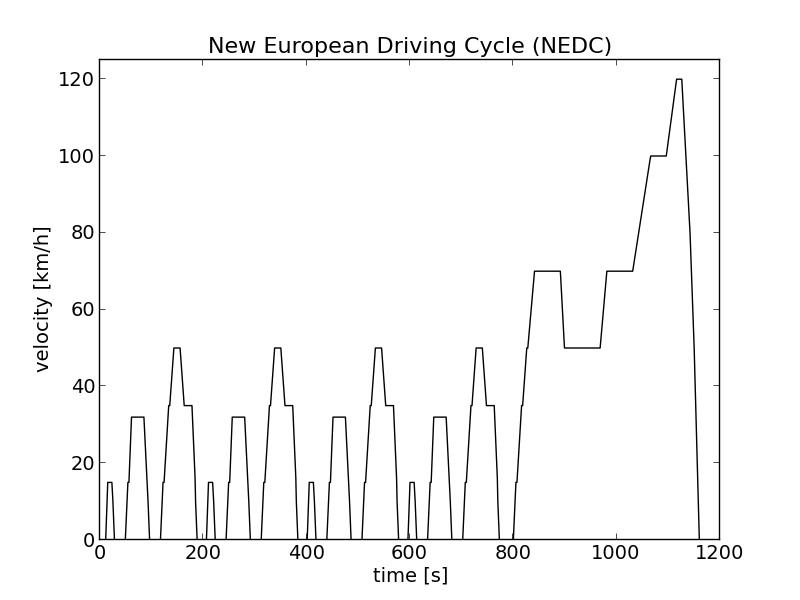 |
plot_csv_timeline.py \-i nefz.csv -c 1 --no-legend --xlabel "time [s]" \--ylabel "velocity [km/h]" --xlabelsize 14 --ylabelsize 14 \--xticks 14 --yticks 14 --colors k --ylim 0,125 \--output nefz.png \--title "New European Driving Cycle (NEDC)" --titlesize 16The example shows the New European Driving Cycle (NEDC). |
Options
| Option | Description |
|---|---|
| -i <FILE> --input <FILE> |
Defines the input file to use |
| -c <INT>[,<INT>]* --columns <INT>[,<INT>]* |
Defines which columns shall be plotted |
| -v --verbose |
If set, the progress is printed on the screen |
plot_csv_pie.py#
plot_csv_pie.py reads a .csv file that is assumed to contain a name in the first and an according value in the second column. The read name/value-pairs are visualised as a pie chart.
| Output | Command |
|---|---|
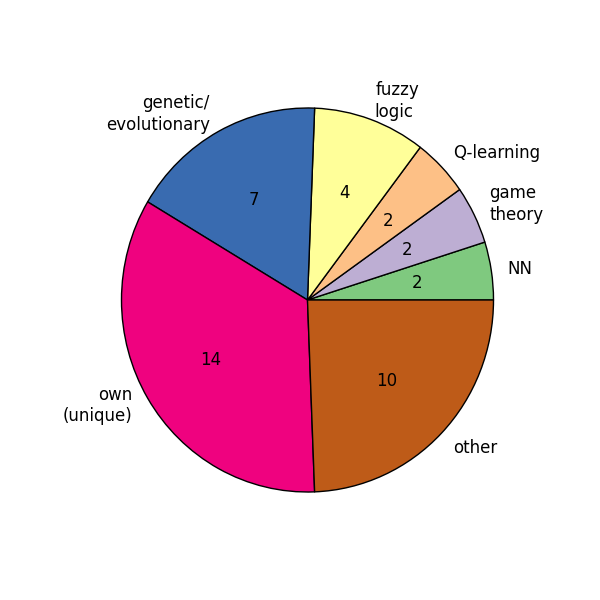 |
plot_csv_pie.py \-i paradigm.csv -b --colormap Accent --no-legend -s 6,6Note: Please note that you should set the width and the height to the same value using the --size \<FLOAT>,\<FLOAT> option, see #common options. Otherwise you'll get an oval. |
Options
| Option | Description |
|---|---|
| -i <FILE> --input <FILE> |
Defines the input file to read |
| -p --percentage |
Interprets read measures as percentages |
| -r --revert |
Reverts the order of read values before plotting them |
| --no-labels | Does not plot the labels |
| --shadow | Puts a shadow below the circle |
| --startangle <FLOAT> | Sets the start angle |
| -v --verbose |
If set, the progress is printed on the screen |
plot_csv_bars.py#
plot_csv_bars.py reads a .csv file that is assumed to contain a name in the first and an according value in the second column. The read name/value-pairs are visualised as a bar chart.
| Output | Command |
|---|---|
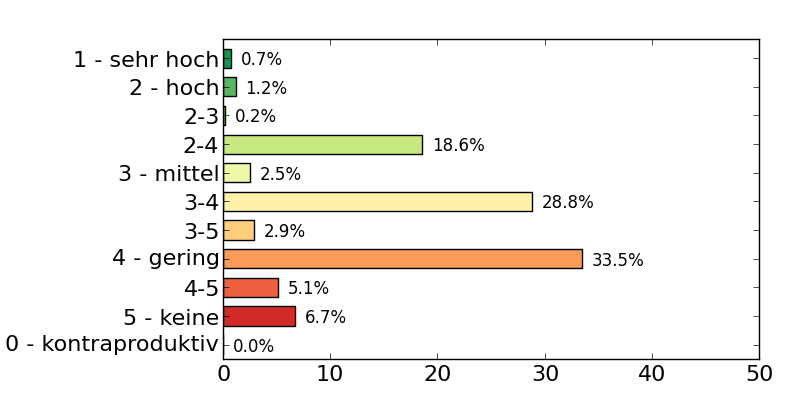 |
plot_csv_bars.py \-i nox_effects.txt --colormap RdYlGn --no-legend --width .4 \-s 8,4 --revert --xlim 0,50 --xticks 0,51,10,16 --yticks 16 \--adjust .28,.1,.95,.9 --show-values |
Options
| Option | Description |
|---|---|
| -i <FILE> --input <FILE> |
Defines the csv file to use as input |
| -x <INT> --column <INT> |
Defines which column of the read .csv-file shall be plotted; default: 1 |
| -r --revert |
Reverts the order of read values before plotting them |
| -w <FLOAT> --width <FLOAT> |
Defines the width of the bars; default: .8 |
| --space <FLOAT> | Defines the space between the bars; default: .2 |
| --norm <FLOAT> | Defines a number by which read values are divided; default: 1.0 |
| --show-values | Shows the values |
| --values-offset <FLOAT> | Position offset for values |
| --vertical | Draws vertical bars (default are horizontal bars) |
| --no-labels | Does not plot the labels |
| -v --verbose |
If set, the progress is printed on the screen |
macrOutput.py#
This tool will plot EdgeData output as fundamental diagram graphs (volume-density, speed-density and volume-speed relations, each edge and lane-based). This requires the EdgeData input file to have interval data with sampledSeconds, density, laneDensity and speed attributes. The tool supports the common options. The output is interpreted as a directory rather than a file, though. The output file names are given as:
- Edge_vk.png (speed-density relation)
- Edge_qk.png (volume-density relation)
- Edge_qv.png (volume-speed relation)
- Lane_vk.png (speed-density relation)
- Lane_qk.png (volume-density relation)
- Lane_qv.png (volume-speed relation)
Example call: python macrOutput.py edgeData.xml
common options#
The following options are common to all previously listed tools. They can be divided into two groups:
- options for formatting the figure (including adding captions etc.)
- options for determining what to do with the generated figure
The options are listed and discussed in the following sub-sections, respectively.
Formatting Options#
| Option | Description |
|---|---|
| --colors <COLOR> | Uses the given colors; the number of given colors must be the same as the number of measures to plot |
| --colormap <STRING> | Uses the named colormap |
--labels <LABELS>-l <LABELS> |
Uses the given labels; the number of given labels must be the same as the number of measures to plot |
--xlim <XMIN>,<XMAX> |
Describes the limits of the figure along the x-axis |
--ylim <YMIN>,<YMAX> |
Describes the limits of the figure along the y-axis |
--xticks <XMIN>,<XMAX>,<XSTEP>,<XSIZE>--yticks <XSIZE> |
If only one number is given, it is interpreted as the size of the tick labels on the x-axis; if four numbers are given, they are interpreted as the lowest ticks position, the highest ticks position, the step between ticks, and the tick's size, respectively, all along the x-axis |
--yticks <XMIN>,<XMAX>,<XSTEP>,<XSIZE> --yticks <XSIZE> |
If only one number is given, it is interpreted as the size of the tick labels on the y-axis; if four numbers are given, they are interpreted as the lowest ticks position, the highest ticks position, the step between ticks, and the tick's size, respectively, all along the y-axis |
| --xtime0 | If set, the tick labels along the x-axis are formatted as time entries (hh) |
| --ytime0 | If set, the tick labels along the y-axis are formatted as time entries (hh) |
| --xtime1 | If set, the tick labels along the x-axis are formatted as time entries (hh:mm) |
| --ytime1 | If set, the tick labels along the y-axis are formatted as time entries (hh:mm) |
| --xtime2 | If set, the tick labels along the x-axis are formatted as time entries (hh:mm:ss) |
| --ytime2 | If set, the tick labels along the y-axis are formatted as time entries (hh:mm:ss) |
| --xgrid | If set, a grid along the ticks on the x-axis is drawn |
| --ygrid | If set, a grid along the ticks on the y-axis is drawn |
| --xticksorientation <FLOAT> | The orientation of the x-ticks (in °); default: matplotlib default |
| --yticksorientation <FLOAT> | The orientation of the y-ticks (in °); default: matplotlib default |
| --xlabel <STRING> | Defines the label to set for the x-axis |
| --ylabel <STRING> | Defines the label to set for the y-axis |
| --xlabelsize <FLOAT> | Defines the size of the label of the x-axis |
| --ylabelsize <FLOAT> | Defines the size of the label of the y-axis |
| --marker <STRING> | Matplotlib marker style for drawing points; default: 'o' for dots in scatter plot, otherwise not used |
| --linestyle <STRING> | Matplotlib line style for drawing lines; default: '-' for continuous lines |
| --title <STRING> | Defines the title of the figure |
| --titlesize <FLOAT> | Defines the size of the title |
| --adjust <FLOAT>,<FLOAT> --adjust <FLOAT>,<FLOAT>,<FLOAT>,<FLOAT> |
Adjust the plot; If two floats are given, they are interpreted as left and bottom values, if four numbers are given, they are interpreted as left, bottom, right, top |
| --size <FLOAT>,<FLOAT> | Defines the size of figure |
| --no-legend | If set, no legend is drawn |
| --legend-position <STRING> | Defines the position of the legend; default: matplolib default |
| --alpha <FLOAT> | Defines the opacity of the plot background in the range 0=fully transparent to 1=opaque; default: 1 |
Interaction Options#
If one of the scripts is simply started with no options that are listed below, the figure will be shown. To write the figure additionally into a file, the filename to generate must be given using the --output <FILE> (or -o <FILE> for short).
If the script is run in a batch file, it is often not convenient to show the figure (once known it is as it should be). In such cases, the option --blind (-b) can be used that suppresses showing the figure.
| Option | Description |
|---|---|
| -o <FILE> --output <FILE> |
Defines the name under which the figure shall be saved |
| -b --blind |
If set, the figure will not be shown |
Further Visualization Methods#
Coloring and scaling edges in sumo-gui according to arbitrary data#
sumo-gui can load edgeData files and use the contained values of any attribute for coloring edges (roads) as well as for modifying the visual width of the edges. This serves a similar use case as plot_net_dump.py but allows all dynamic zooming and panning features of of sumo-gui.
When stepping through the simulation, different time intervals contained in the weight file can be shown. It can be useful to adapt the simulation step length to the data period for easier stepping:
sumo-gui -n NET --edgedata-files FILE --step-length 3600 --end 24:0:0
After that, you need to do the following settings:
- Choose "edgeData" for coloring:
- Choose the data type and recalibrate the interval thresholds for coloring:
- Set color edge legend (optional):
Regarding "Recalibrate Rainbow" it is done with use of the data read in the current step. So, it may be needed to run some steps to get data sometimes before klicking "Recalibrate Rainbow". Moreover, the result may be different if data in another step are used. Alternatively, you can (1) set min and max next to the icon "Recalibrate Rainbow" directly or (2) set the interval threshold for each interval manuelly.
Intersection Flow Diagram#
To visualize the flow on an intersection with line widths according to the amount of traffic, the tool route2poly.py can be used.
- Use netedit to select all edges at one or more intersection for which the flow shall be visualized and save the selection to a file (e.g. sel.txt)
-
generate polygons with widths according to the number of vehicles passing the selected edges. When setting --scale-width to 0.01, 100 vehicles using the same edge sequence will correspond to a polygon width of 1m. The option --spread is used to prevent overlapping of the generated polygons and should be adapted according to the polygon width.
route2poly.py NET routes.rou.xml -o flows.poly.xml --filter-output.file sel.txt --scale-width 0.01 --internal --spread 1 --hue cycle -
visualize the flows in sumo-gui
sumo-gui -n NET -a flows.poly.xml
Visulizing FCD-Data as moving POIs#
The tool fcdReplay.py can be used to replay an fcd-output file in sumo-gui.
Example uses:
python tools/fcdReplay.py -k example.sumocfg -f fcd.xml
To make use of fcd data with lon/lat values (generated with sumo option --fcd-output.geo), the option --geo must be set. With the option --fcd-output.utm the vehicle positions in the FCD output are given in UTM coordinates.
Outdated#
The tools are meant to be named as following: <API>__<DESCRIPTION>.py, where:
- <API>: mpl for matplotlib
- : the SUMO-output that is processed (mainly)
- <DESCRIPTION>: what the tool does
mpl_dump_twoAgainst.py#
Reads two dump files (mandatory options --dump1 <FILE> and --dump2 <FILE>, or, for short -1 <FILE> and -2 <FILE>). Extracts the value described by --value (default: speed). Plots the values of dump2 over the according (same interval time and edge) values from dump1.
Either shows the plot (when --show is set) or saves it into a file (when --output <FILE> is set).
You can additionally plot the normed sums of the value using (--join). In the other case, you can try to use --time-coloring to assign different colors to the read intervals.
You can format the axes by using --xticks <XMIN,XMAX,XSTEP,FONTSIZE> and --yticks <YMIN,YMAX,YSTEP,FONTSIZE> and set theit limits using --xlim <XMIN,XMAX> and --ylim <YMIN,YMAX>. The output size of the image may be set using --size <WIDTH,HEIGHT>.
mpl_tripinfos_twoAgainst.py#
Reads two tripinfos files (mandatory options --tripinfos1 <FILE> and --tripinfos2 <FILE>, or, for short -1 <FILE> and -2 <FILE>). Extracts the value described by --value (default: duration). Plots the values of tripinfos2 over the according (same vehicle) values from tripinfos1.
Either shows the plot (when --show is set) or saves it into a file (when --output <FILE> is set).
You can format the axes by using --xticks <XMIN,XMAX,XSTEP,FONTSIZE> and --yticks <YMIN,YMAX,YSTEP,FONTSIZE> and set theit limits using --xlim <XMIN,XMAX> and --ylim <YMIN,YMAX>. The output size of the image may be set using --size <WIDTH,HEIGHT>.
mpl_dump_timeline.py#
Reads a value (given as --value <VALUE>, default speed) for edges defined via --edges <EDGEID>[,<EDGEID>]* from the dumps defined via --dumps <DUMP>[,<DUMP>]*. Plots them as time lines, using the colors defined via --colors <MPL_COLOR>[,<MPLCOLOR>]*. Please note that the number of colors must be equal to number of edges * number of dumps.
Either shows the plot (when --show is set) or saves it into a file (when --output <FILENAME> is set).
You can format the axes by using --xticks <XMIN,XMAX,XSTEP,FONTSIZE> and --yticks <YMIN,YMAX,YSTEP,FONTSIZE> and set theit limits using --xlim <XMIN,XMAX> and --ylim <YMIN,YMAX>. The output size of the image may be set using --size <WIDTH,HEIGHT>.
mpl_dump_onNet.py#
Reads a network (defined using --net-file <NET> or -n <NET>) and an edge-dump file (--dump <DUMPFILE> or -d <DUMP_FILE>). Plots the network using the geometries read from <NET>. Both the width and the colors used for each edge are determined using --value <WIDTHVALUE>,<COLORVALUE> where both <WIDTHVALUE> and <COLORVALUE> are attributes within the dump-file that exist for each edge.
You can change the used color map by setting --color-map <DEFINITION>. <DEFINITION> is made of a sorted list of values (between 0 and 1) and assigned colors. This means that the default 0:#ff0000,.5:#ffff00,1:#00ff00 let streets with low value for <COLORVALUE> appear red, for those in the middle yellow and for those with a high value green. For values between the given values, the color is determined using linear interpolation. Please note that only lowercase hexadecimal characters may be used.
Either shows the plot (when --show is set) or saves it into a file (when --output <FILENAME> is set).
--join sums up the values found for each edge and divides the result by the number of these values. If join is not set and --output is given, one should choose an output name which looks as following: <NAME>'%05d.png. The %05d will be replaced by the current time step written.
If you have generated a set of images by not "joining" (aggregating) the data, you can convert the obtained pictures into an animated gif using ImageMagick and the following command:
convert -delay 20 *.png -loop 0 animation.gif
(loop 0 means that the animation repeats from begin after the end)
You can format the axes by using --xticks <XMIN,XMAX,XSTEP,FONTSIZE> and --yticks <YMIN,YMAX,YSTEP,FONTSIZE> and set theit limits using --xlim <XMIN,XMAX> and --ylim <YMIN,YMAX>. The output size of the image may be set using --size <WIDTH,HEIGHT>.